- 89 Indiana University undergraduates - Course credit participation - Random assignment to conditions (REP or NREP) - Normal or corrected vision
- 304 Indiana University students - Random assignment to conditions (low, medium, high, or mixed distortion)
146 IU Students
Training Stage
Training Stage
Training Stage
Training Stage
• Procedure
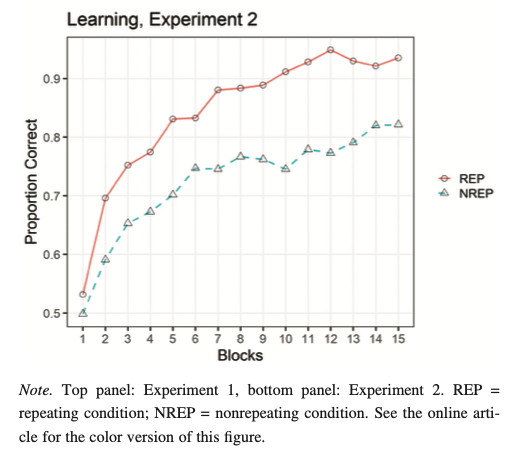
- REP Condition: 15 unique patterns (5 per category), repeated across 15 blocks (225 trials total) - NREP Condition: 75 unique patterns (5 per category per block), no repetitions (225 trials total)
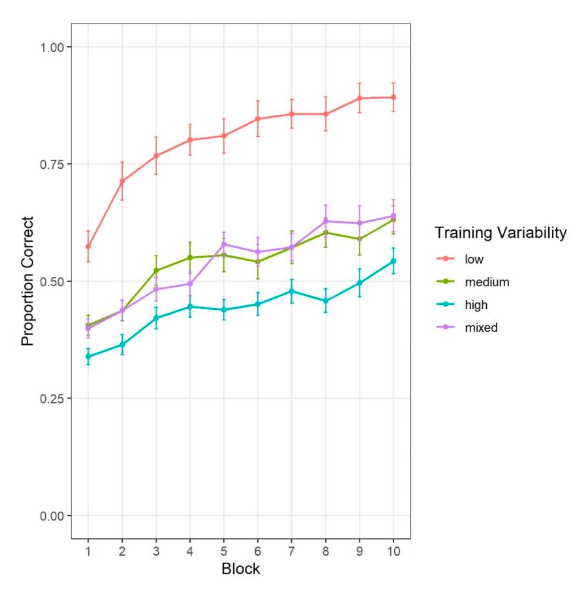
- 10 blocks, 27 trials each (270 trials total) - Different set of training patterns in each block - Corrective feedback for 2 seconds after each response
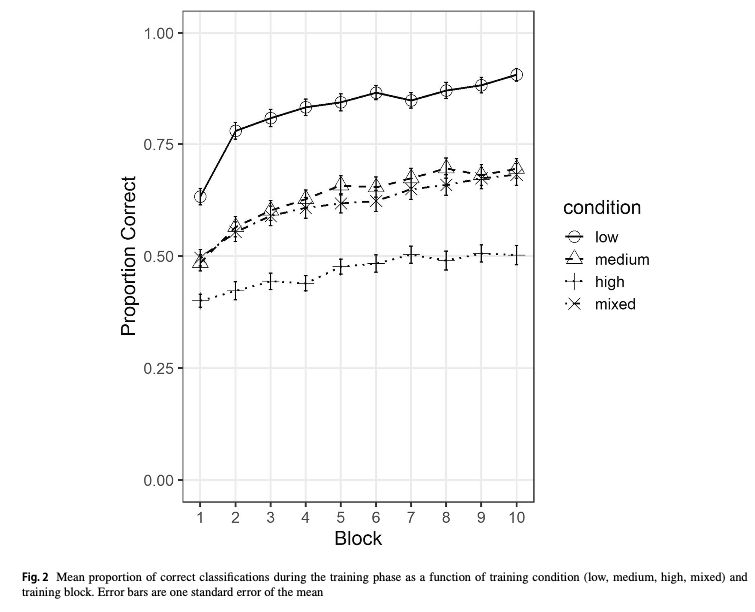
- Training patterns repeated across 10 blocks with randomized presentation order within each block - Four between-subject conditions: low, medium, high, and mixed distortion levels
• Stimuli
- 15 or 75 unique dot patterns (depending on condition) - Created using Posner (1967) procedure
- 270 unique training patterns
- 27 unique dot patterns (9 per category)
Testing Stage
Transfer Phase
Testing Stage
Testing Stage
• Procedure
- 63 trials total - Random order of presentation
- 84 trials total - Random order of presentation
- 87 trials total - Random order of presentation
• Stimuli
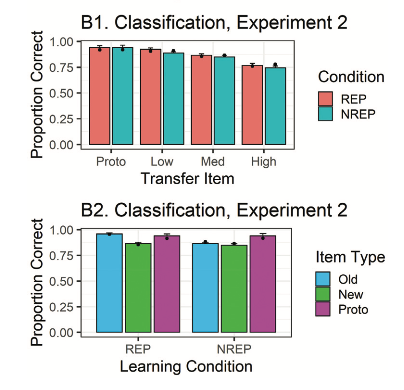
- 15 old distortions (5 per category) - 3 prototypes (one per category) - 15 low-level distortions (5 per category) - 15 new medium-level distortions (5 per category) - 15 high-level distortions (5 per category)
- 27 old patterns from the training phase (9 per category) - 3 prototypes (one per category) - 9 new low-level distortions (3 per category) - 18 new medium-level distortions (6 per category) - 27 new high-level distortions (9 per category)
- 27 old distortions (9 per category) - 3 prototypes (1 per category) - 9 new low-level distortions (3 per category) - 18
Notes:
REP: Repeating Protocol
NREP: Nonrepeating Protocol
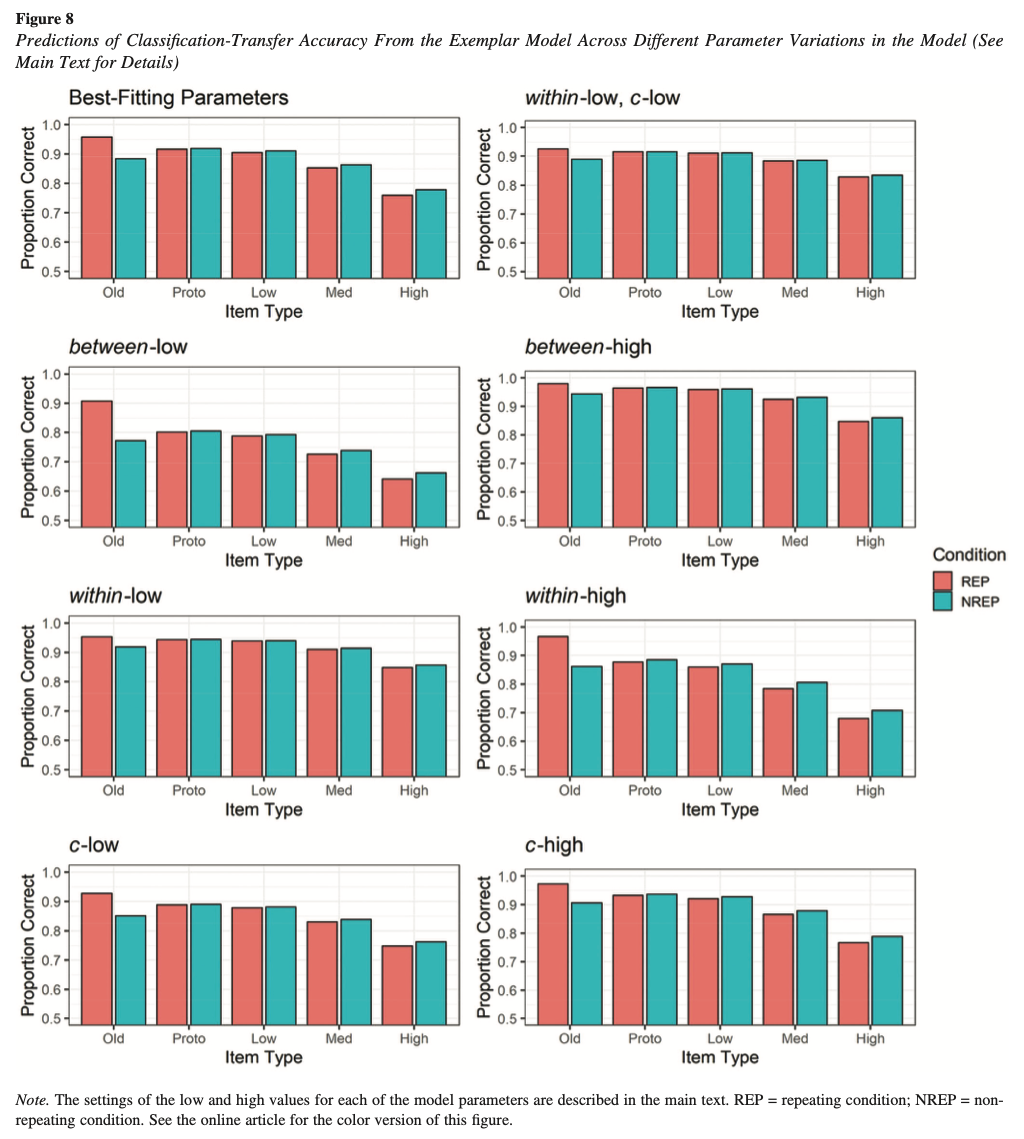
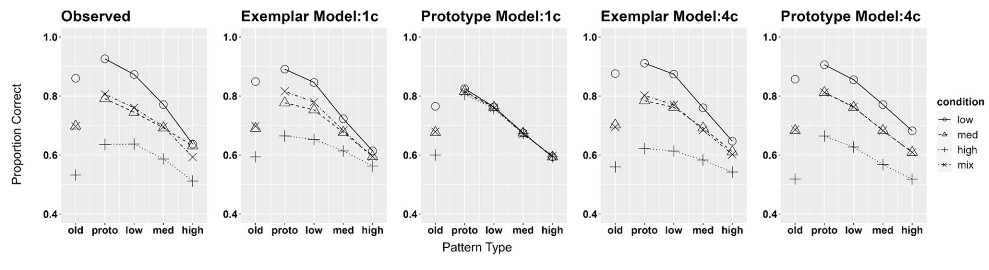
Hu & Nosofsky (2022) investigated the effects of repeating vs. nonrepeating training patterns on category learning and generalization.
Hu & Nosofsky (2024) examined the impact of different training distortion levels on category learning and generalization. Each subject has unique prototype set.
Fixed Prototype Pilot Study examined the impact of different training distortion levels on category learning and generalization. Fixed set of prototypes across all subjects.
All studies used a dot pattern categorization paradigm where participants learned to classify patterns into categories based on visual similarity.
Dot pattern distortions were created using a modified Posner-Keele (1968) procedure. Low, medium and high distortions displaced the dots by an average of 4, 6, and 7.7 Posner-levels respectively.
Display code
pacman::p_load(dplyr,purrr,tidyr,ggplot2,readr,here, patchwork, conflicted,ggh4x,gt)conflict_prefer_all("dplyr", quiet =TRUE)source(here::here("R/fun_plot.R"))lmc22<-readRDS(here("data","lmc22.rds"))|>mutate(Pattern_Token =case_when(Pattern.Type=="Trained.Med"~"old",Pattern.Type2=="Prototype"~"prototype",Pattern.Type2=="New.Low"~"new_low",Pattern.Type2=="New.Med"~"new_med",Pattern.Type2=="New.High"~"new_high"))|># set phase="Training" when Phase==1, and phase="Test" when Phase==2mutate(phase =case_when(Phase==1~"Training",Phase==2~"Test"), Stage =case_when(Stage=="Med"~"Middle",TRUE~Stage))mc24<-readRDS(here("data","mc24.rds"))fp24<-readRDS(here("data","fixed_proto24.rds"))|>mutate(Stage =case_when(phase=="Test"~"Test",TRUE~Stage))all_data<-fp24|>select(-pool_index)|>rbind(mc24)|>rbind(lmc22)all_data$Pattern_Token=factor(all_data$Pattern_Token,levels=c("old","prototype","new_low","new_med","new_high","special"))all_data$condit=factor(all_data$condit,levels=c("low","medium","mixed","high","nrep","rep"))all_data$exp=factor(all_data$exp,levels=c("lmc22","mc24","fixed_proto"))all_data$exp2=factor(all_data$exp,labels=c("Hu & Nosofsky 2022","Hu & Nosofsky 2024","Fixed Prototype Pilot"))all_data$Stage=factor(all_data$Stage,levels=c("Start","Middle","End","Test"))all_data$phase=factor(all_data$phase,levels=c("Training","Test"))theme_set(theme_nice())yt<-round(seq(0,1,length.out=7), 2)xt<-seq(1,10,1)eg<-list(geom_hline(yintercept =c(.33, .66),linetype="dashed", alpha=.5),scale_y_continuous(breaks=yt,limits=c(0,1)),scale_x_continuous(breaks=xt))dtf<-all_data|>filter(Stage=="End")|>group_by(sbjCode, condit, Pattern_Token,exp2,Stage,Phase,phase)|>summarize(propCor=mean(Corr))|>arrange(-propCor)|>group_by(exp2,condit)|># bin into quartile by propCormutate(quartile =ntile(propCor, 4), finalTrain=propCor)all_data<-all_data|>select(-quartile)|># remove original quartile varleft_join(dtf|>select(sbjCode,condit,quartile,exp2), by=c("sbjCode","condit","exp2"))html<-ifelse(knitr::pandoc_to()%in%c("html"), TRUE, FALSE)out_type<-knitr::opts_knit$get("rmarkdown.pandoc.to")if(html){fw=11;rel_size=.70;}else{fw=8;rel_size=.5}print(fw)
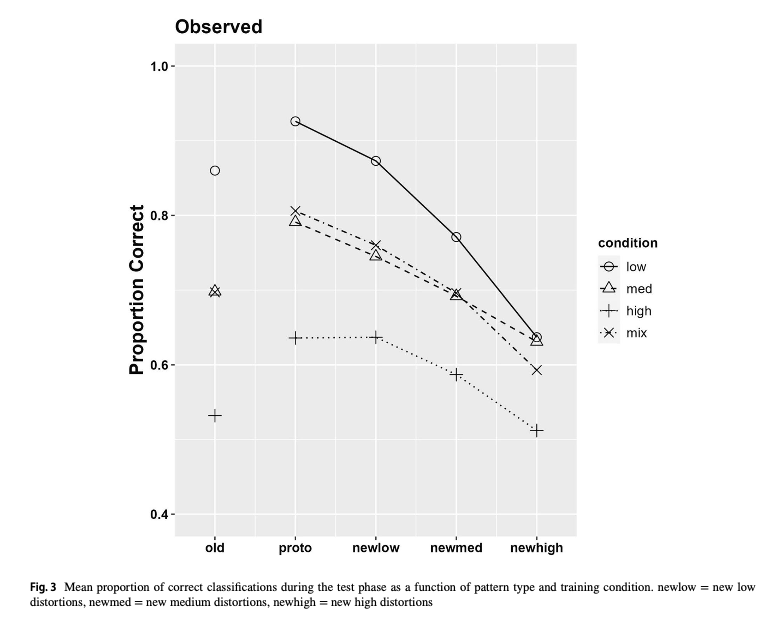
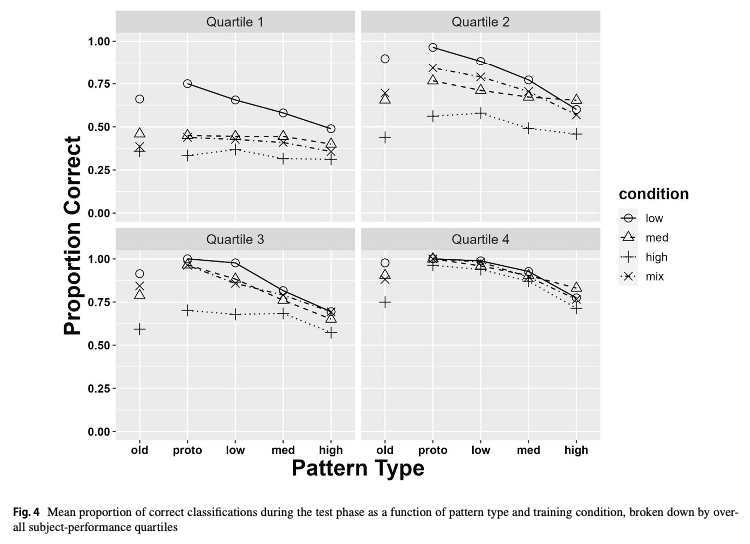
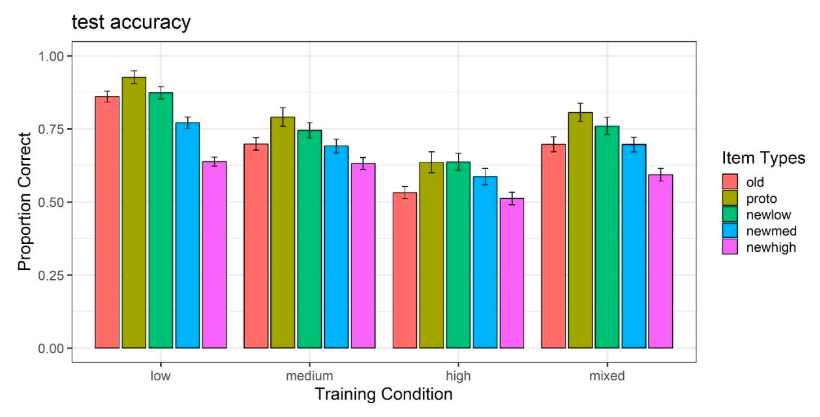
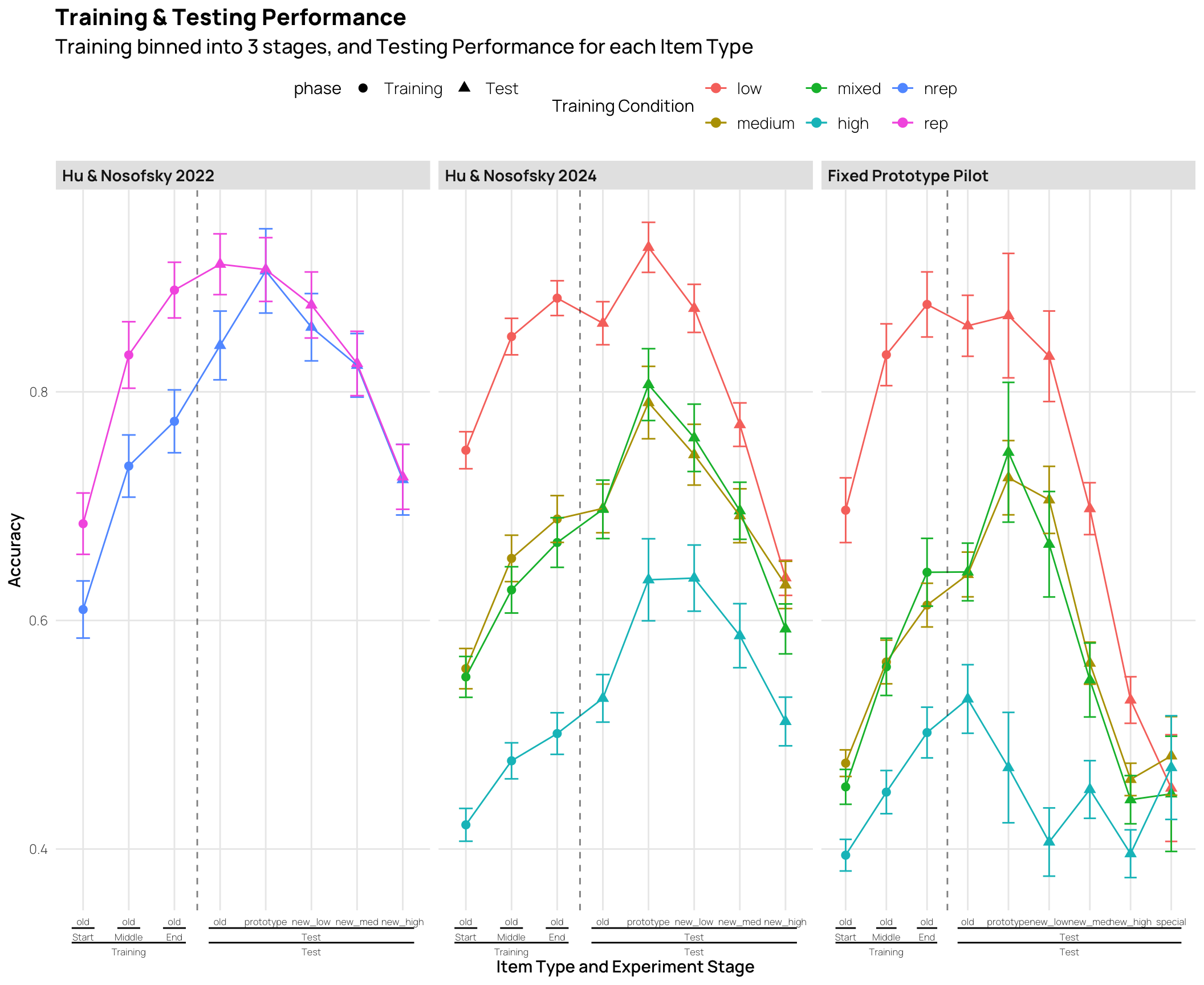
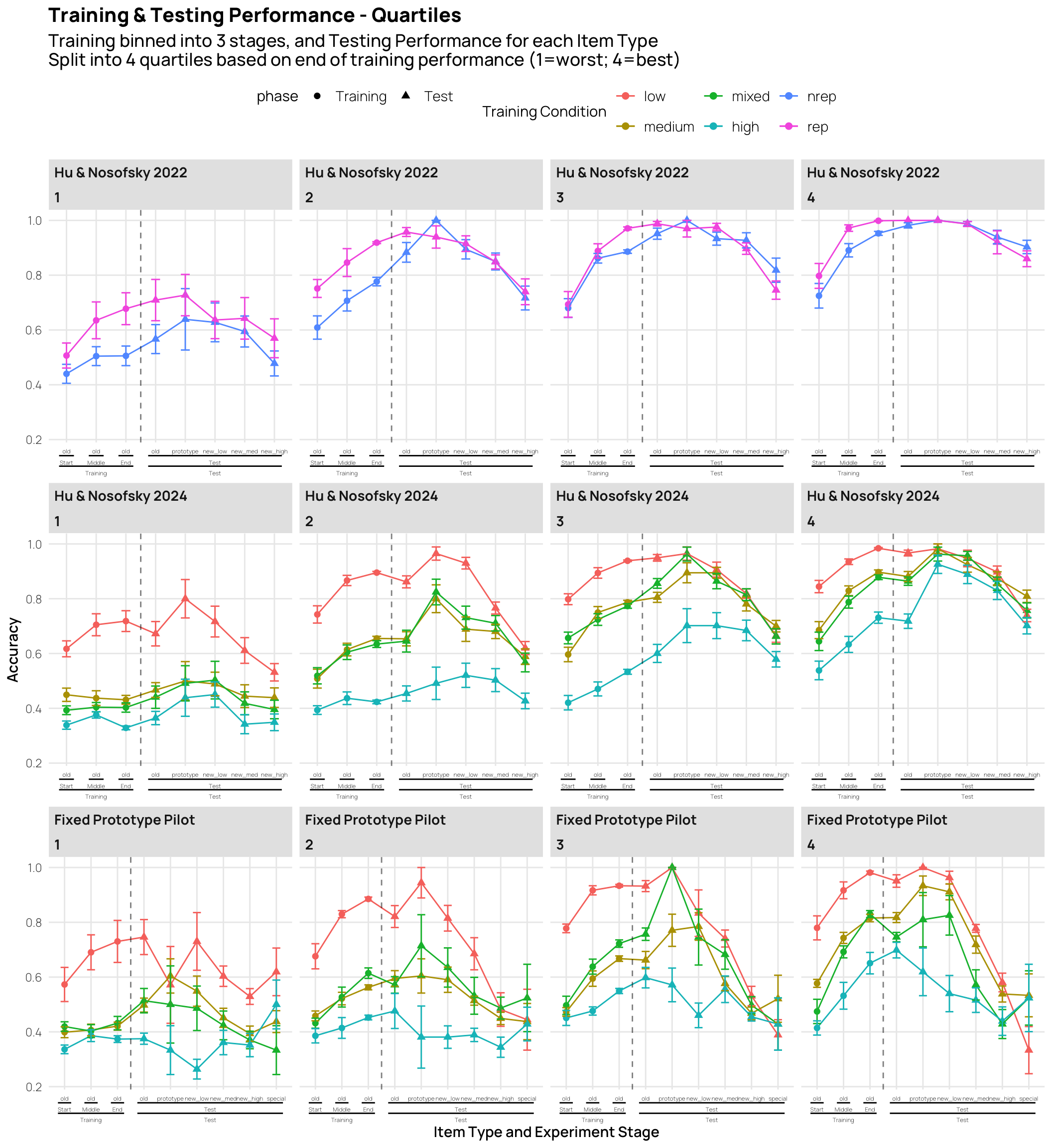
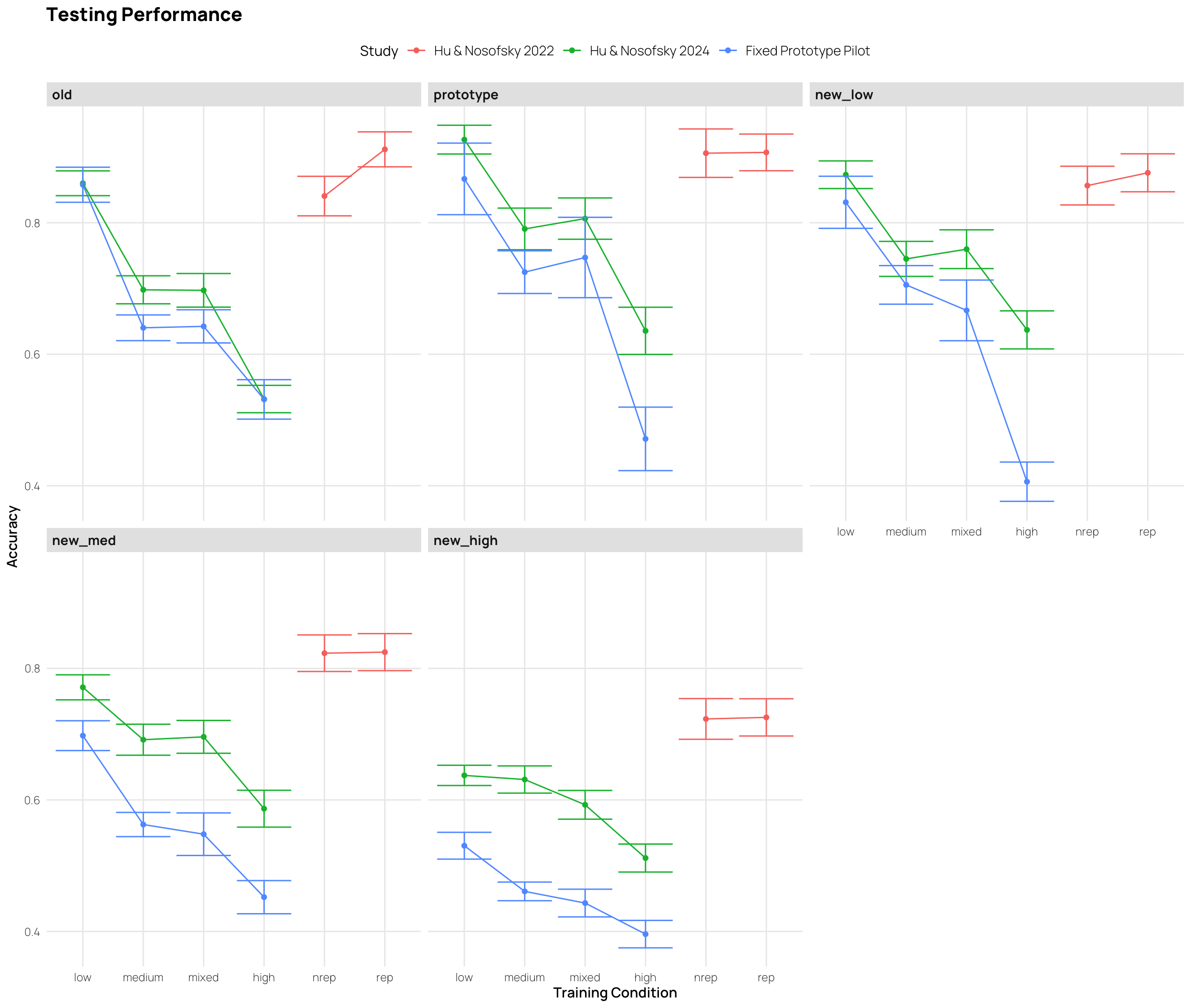
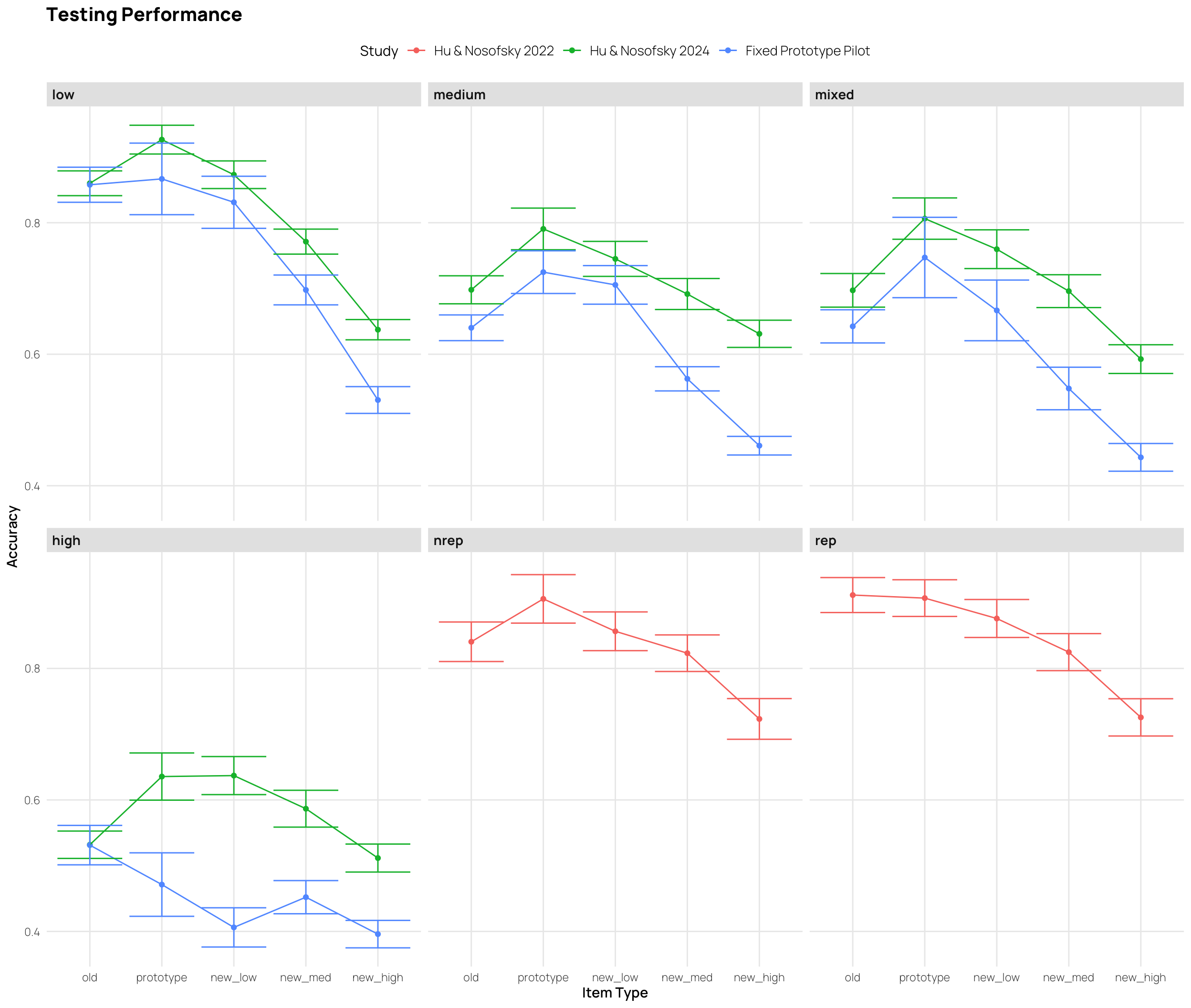
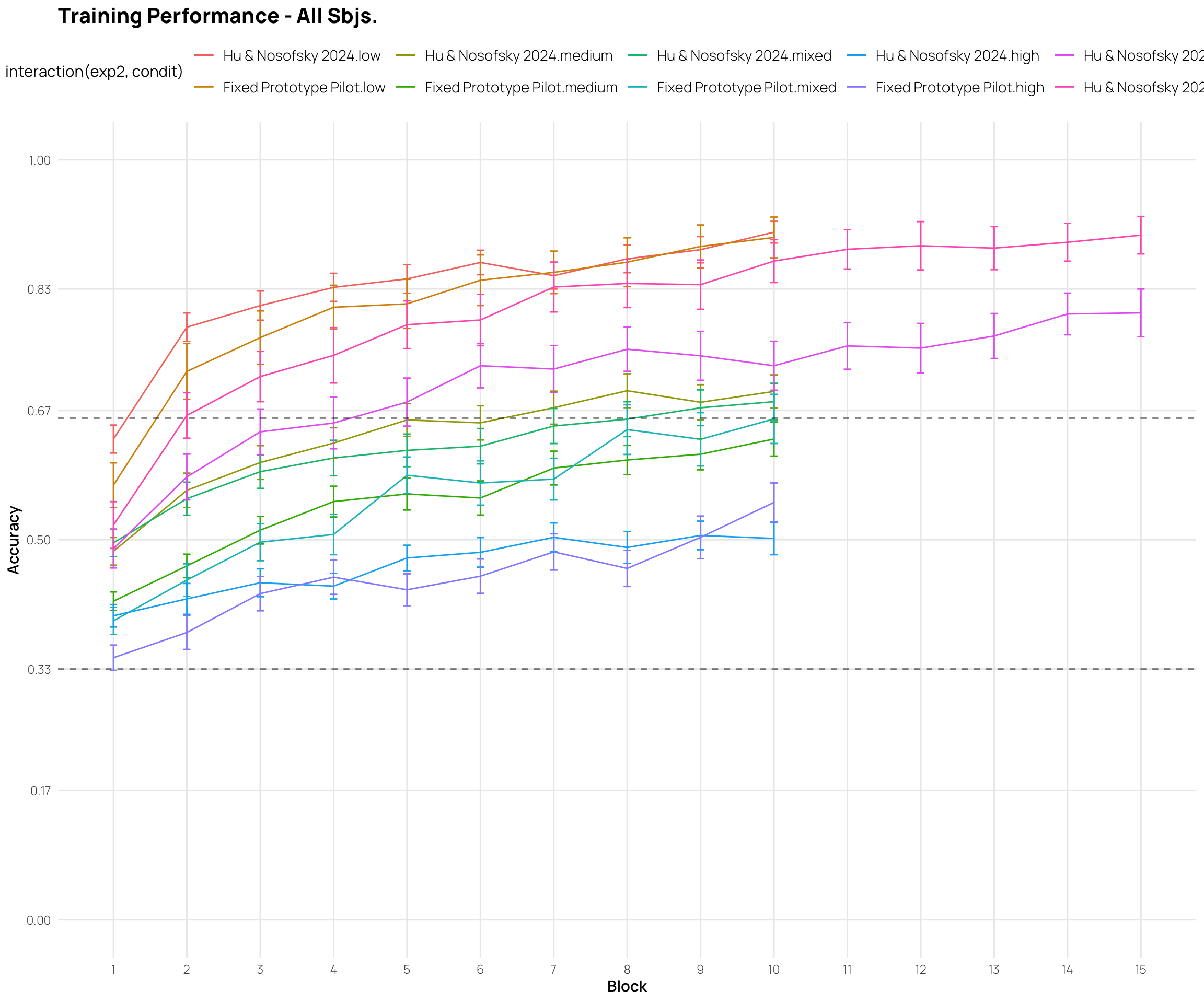
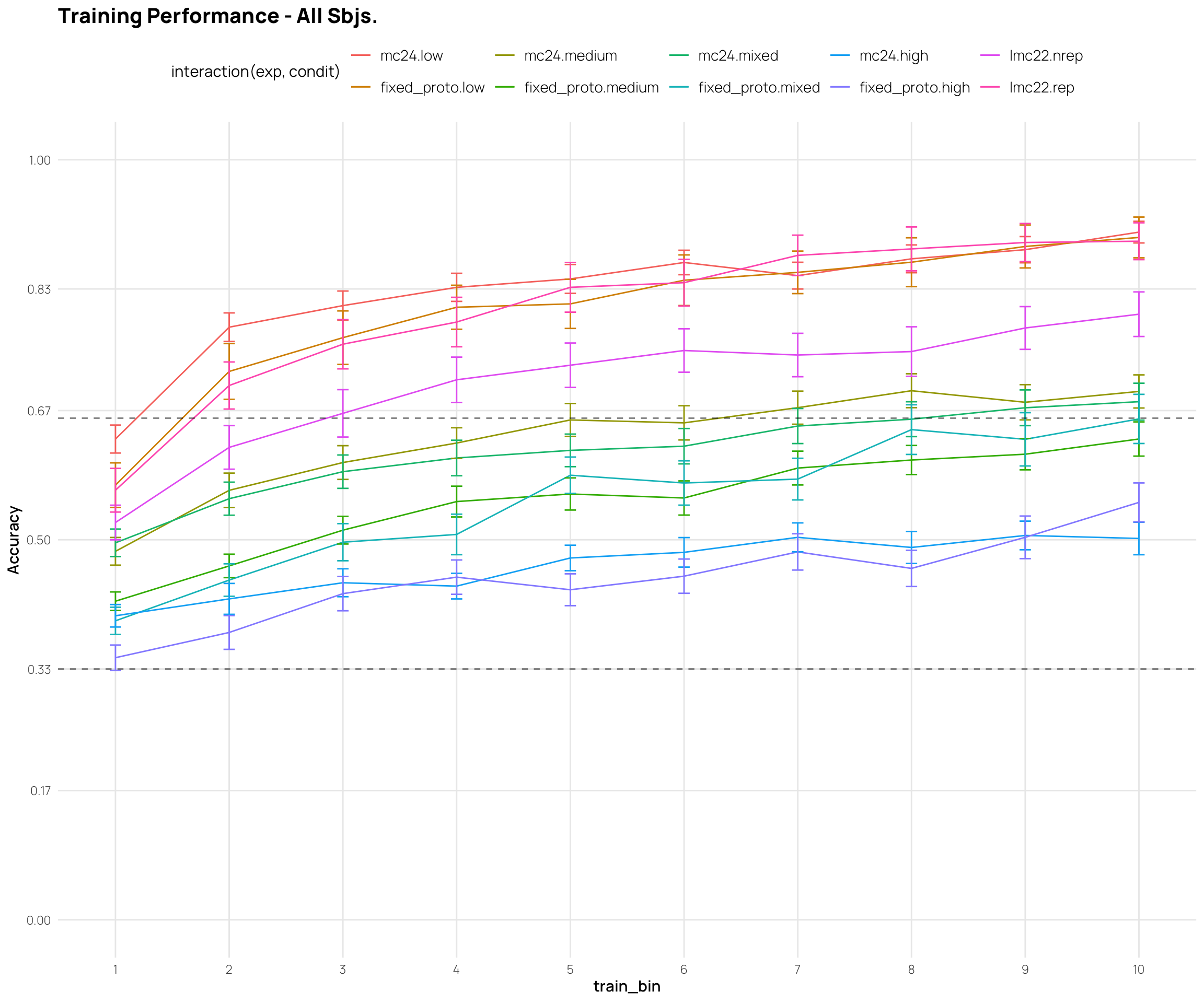
These plots show mean performance at the start, middle and end of training (first 3 points), and the testing performance for each item type (final 5 points).
The pilot study included “special” patterns, that were predicted to be more difficult.
click on plots to enlarge
Display code
if(html)theme_set(theme_nice())elsetheme_set(theme_nice_pdf())all_data|># filter(Pattern_Token != "special") |> group_by(sbjCode, condit, Pattern_Token,exp2,Stage,Phase,phase)|>summarize(Corr=mean(Corr))|>group_by(condit,Pattern_Token,exp2,Stage,Phase,phase)|>summarise(empirical_stat =mean(Corr), sem =sd(Corr)/sqrt(length(Corr)), ci_lower =mean(Corr)-sem, ci_upper =mean(Corr)+sem)|>mutate(method ="standard error")|>ggplot(aes(x=interaction(Pattern_Token,Stage,phase), y=empirical_stat, col=condit, group=condit))+geom_point(aes(shape=phase),size=2.5)+geom_line(aes(group =condit))+geom_errorbar(aes(ymin =ci_lower, ymax =ci_upper),width=.3)+geom_vline(xintercept=c(3.5),linetype="dashed", alpha=.5)+facet_wrap(~exp2,scale="free_x")+labs(x="Item Type and Experiment Stage",y="Accuracy",col="Training Condition",title="Training & Testing Performance", subtitle="Training binned into 3 stages, and Testing Performance for each Item Type")+theme(ggh4x.axis.nestline =element_line(colour ="black"), axis.text.x =element_text(face ="plain", size =rel(rel_size)))+scale_x_discrete(guide ="axis_nested")
Display code
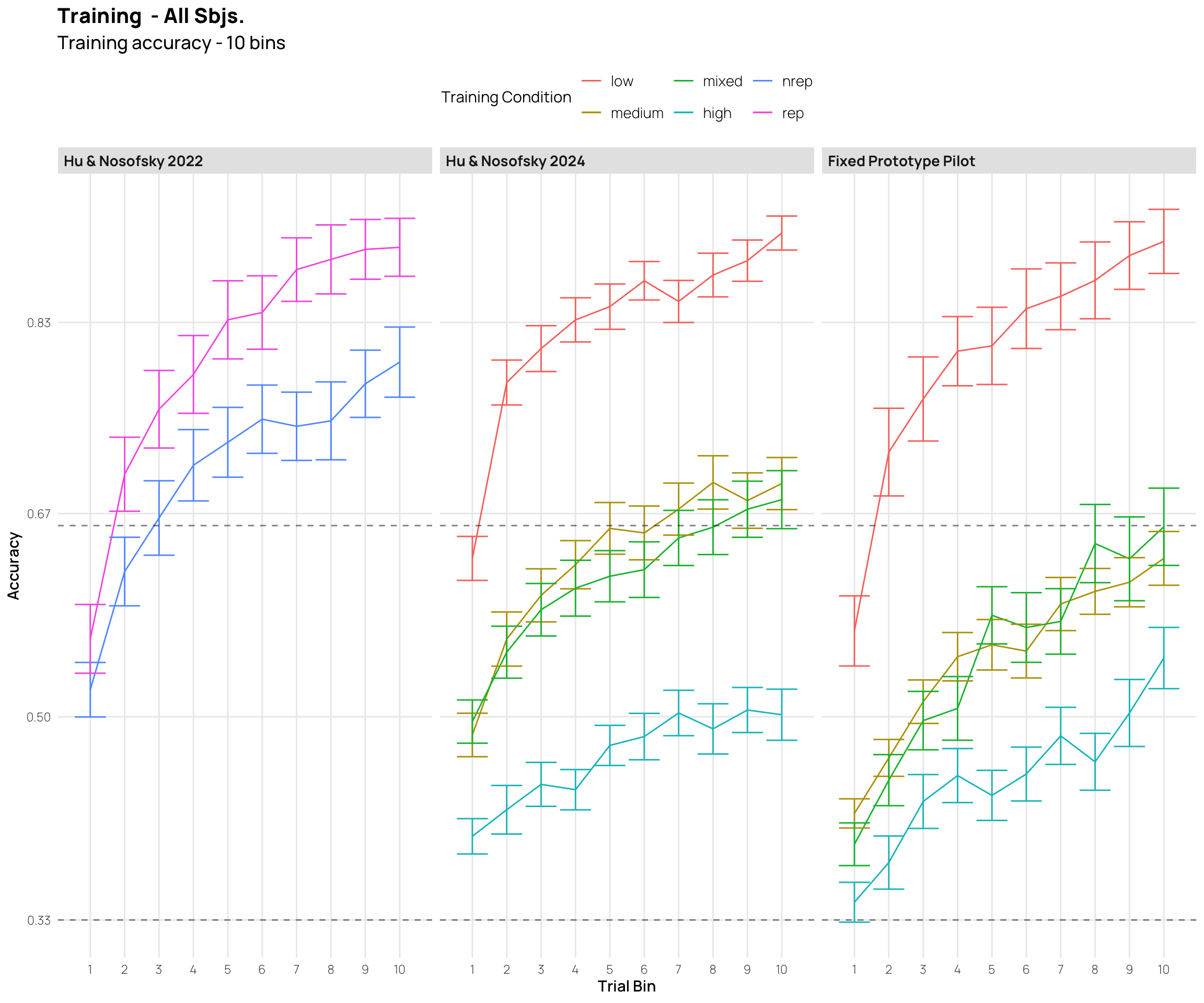
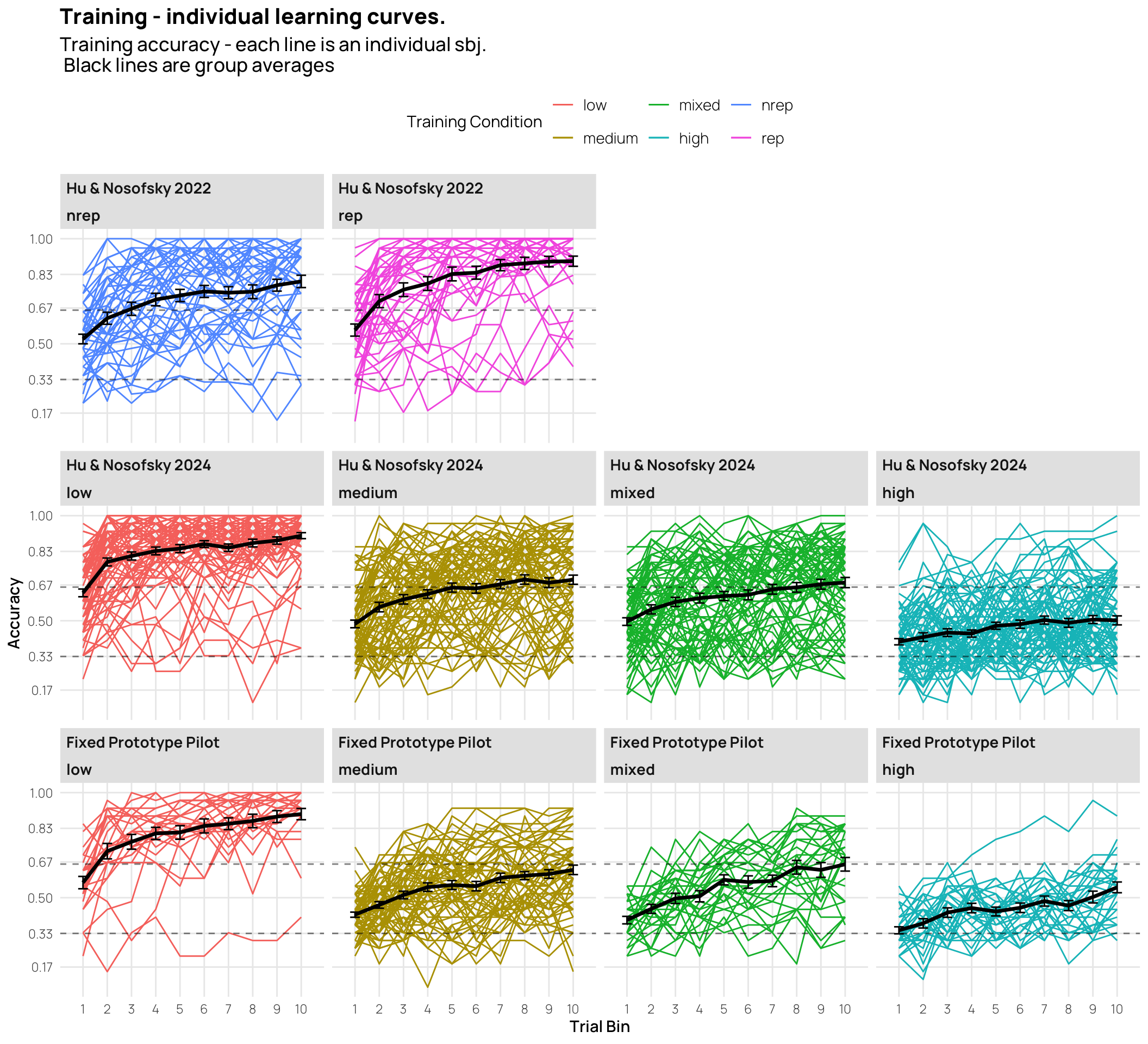
all_data|>#filter(Pattern_Token != "special") |> group_by(sbjCode, condit, Pattern_Token,exp2,Stage,Phase,phase,quartile)|>summarize(Corr=mean(Corr))|>group_by(condit,Pattern_Token,exp2,Stage,Phase,phase,quartile)|>summarise(empirical_stat =mean(Corr), sem =sd(Corr)/sqrt(length(Corr)), ci_lower =mean(Corr)-sem, ci_upper =mean(Corr)+sem)|>mutate(method ="standard error",quartile=factor(quartile,levels=c("1","2","3","4")))|>ggplot(aes(x=interaction(Pattern_Token,Stage,phase), y=empirical_stat, col=condit, group=condit))+geom_point(aes(shape=phase),size=2.0)+geom_line(aes(group =condit))+geom_errorbar(aes(ymin =ci_lower, ymax =ci_upper),width=.3)+geom_vline(xintercept=c(3.5),linetype="dashed", alpha=.5)+facet_wrap(exp2~quartile,scale="free_x")+labs(x="Item Type and Experiment Stage",y="Accuracy",col="Training Condition",title="Training & Testing Performance - Quartiles", subtitle="Training binned into 3 stages, and Testing Performance for each Item Type\nSplit into 4 quartiles based on end of training performance (1=worst; 4=best)")+theme(ggh4x.axis.nestline =element_line(colour ="black"), axis.text.x =element_text(face ="plain", size =rel(rel_size-.2)))+scale_x_discrete(guide ="axis_nested")
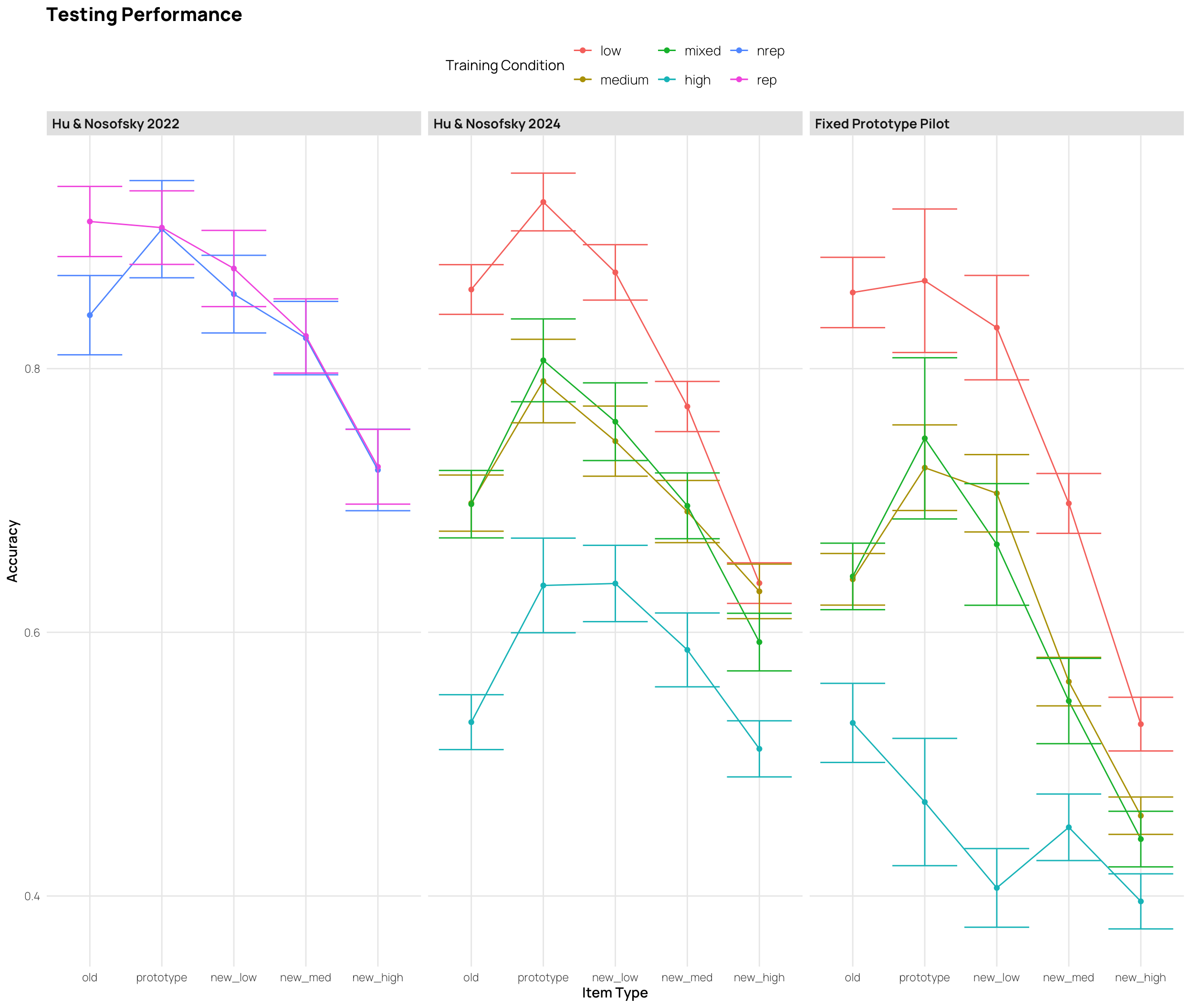
library(stringr)final_data<-all_data|>filter(Pattern_Token!="special", Phase==2)|>group_by(sbjCode, condit, Pattern_Token, exp2, Stage, Phase, phase)|>summarize(Corr =mean(Corr), .groups ="drop")|>group_by(condit, Pattern_Token, exp2, Stage, Phase, phase)|>summarise(empirical_stat =mean(Corr), sem =sd(Corr)/sqrt(n()), ci_lower =mean(Corr)-sem, ci_upper =mean(Corr)+sem, .groups ="drop")|>mutate(mean_sem =paste0(round(empirical_stat, 2), " (", round(sem, 3), ")"), method ="standard error")|>select(condit, Pattern_Token, exp2, phase, mean_sem)# Reshape data to wide format for gt tablefinal_data_wide<-final_data|>pivot_wider(names_from =Pattern_Token, values_from =mean_sem)|>arrange(exp2)# Identify the row indices with the maximum value in each Pattern_Token column within each level of Experimentmax_indices<-final_data_wide|>group_by(exp2)|>summarise(across(starts_with("old")|starts_with("prototype")|starts_with("new_low")|starts_with("new_med")|starts_with("new_high"), ~which.max(as.numeric(str_extract(., "^\\d+\\.\\d+")))))|>pivot_longer(-exp2, names_to ="column", values_to ="row")# Create the gt tablegt_table<-final_data_wide|>gt()|>tab_header( title ="Testing Phase Performance Summary", subtitle ="Mean (SE) for Each Item Type and Condition")|>cols_label( condit ="Condition", exp2 ="Experiment", phase ="Phase", old ="Old", prototype ="Prototype", new_low ="New Low", new_med ="New Medium", new_high ="New High")|>cols_align( align ="center", columns =everything())|>tab_footnote( footnote ="For each experiment, the row with the highest value for each item type is bolded")# Convert exp2 to character for comparisonfinal_data_wide<-final_data_wide|>mutate(exp2 =as.character(exp2))max_indices<-max_indices|>mutate(exp2 =as.character(exp2))# Apply bolding to cells with the maximum valuesfor(iinseq_len(nrow(max_indices))){gt_table<-gt_table|>tab_style( style =cell_text(weight ="bold"), locations =cells_body( columns =all_of(max_indices$column[i]), rows =which(final_data_wide$exp2==max_indices$exp2[i])[max_indices$row[i]]))}# Add darker row borders dividing the experimentsexperiment_levels<-unique(final_data_wide$exp2)row_indices<-which(final_data_wide$exp2!=dplyr::lag(final_data_wide$exp2, default =first(final_data_wide$exp2)))for(row_indexinrow_indices){gt_table<-gt_table|>tab_style( style =cell_borders( sides ="top", color ="black", weight =px(2)), locations =cells_body( rows =row_index))}# Print the tablegt_table
Testing Phase Performance Summary
Mean (SE) for Each Item Type and Condition
Condition
Experiment
Phase
Old
Prototype
New Low
New Medium
New High
nrep
Hu & Nosofsky 2022
Test
0.84 (0.03)
0.91 (0.037)
0.86 (0.029)
0.82 (0.028)
0.72 (0.031)
rep
Hu & Nosofsky 2022
Test
0.91 (0.027)
0.91 (0.028)
0.88 (0.029)
0.82 (0.028)
0.73 (0.028)
low
Hu & Nosofsky 2024
Test
0.86 (0.019)
0.93 (0.022)
0.87 (0.021)
0.77 (0.019)
0.64 (0.015)
medium
Hu & Nosofsky 2024
Test
0.7 (0.021)
0.79 (0.032)
0.75 (0.027)
0.69 (0.024)
0.63 (0.021)
mixed
Hu & Nosofsky 2024
Test
0.7 (0.026)
0.81 (0.031)
0.76 (0.029)
0.7 (0.025)
0.59 (0.022)
high
Hu & Nosofsky 2024
Test
0.53 (0.021)
0.64 (0.036)
0.64 (0.029)
0.59 (0.028)
0.51 (0.021)
low
Fixed Prototype Pilot
Test
0.86 (0.027)
0.87 (0.054)
0.83 (0.04)
0.7 (0.023)
0.53 (0.02)
medium
Fixed Prototype Pilot
Test
0.64 (0.02)
0.72 (0.032)
0.71 (0.029)
0.56 (0.018)
0.46 (0.014)
mixed
Fixed Prototype Pilot
Test
0.64 (0.025)
0.75 (0.061)
0.67 (0.046)
0.55 (0.032)
0.44 (0.021)
high
Fixed Prototype Pilot
Test
0.53 (0.03)
0.47 (0.048)
0.41 (0.03)
0.45 (0.025)
0.4 (0.021)
For each experiment, the row with the highest value for each item type is bolded
References
Hu, M., & Nosofsky, R. M. (2022). Exemplar-model account of categorization and recognition when training instances never repeat. Journal of Experimental Psychology: Learning, Memory, and Cognition, 48(12), 1947–1969. https://doi.org/10.1037/xlm0001008
Hu, M., & Nosofsky, R. M. (2024). High-variability training does not enhance generalization in the prototype-distortion paradigm. Memory & Cognition. https://doi.org/10.3758/s13421-023-01516-1
Source Code
---title: Combined Experimentsauthor:- name: Thomas Gorman url: https://tegorman13.github.io/ orcid: 0000-0001-5366-5442date: last-modifiedlightbox: truetoc: truepage-layout: fullformat: html: grid: sidebar-width: 200px body-width: 1250px margin-width: 140px gutter-width: 1.0rem # hikmah-manuscript-pdf: # echo: false # #output-file: "all_exp.pdf" # mainfont: "Linux Libertine O" # mainfontoptions: # - "Numbers=Proportional" # - "Numbers=OldStyle" # mathfont: "Libertinus Math" pdf: toc: false echo: false #fig-pos: 'H' mathfont: "Libertinus Math" #documentclass: article # papersize: letter fontsize: 9.5pt linestretch: 1.0 geometry: - top=.5in - bottom=.1in - left=.25in - right=.1in - heightrounded docx: echo: false prefer-html: truetoc-depth: 3code-fold: truecode-tools: trueexecute: warning: false eval: true---<br><br>## Paper FiguresRelevant figures from [@huExemplarmodelAccountCategorization2022; @huHighvariabilityTrainingDoes2024]*click on image to enlarge*:::: {.panel-tabset}### 2022 Paper::: {layout-nrow=2}:::### 2024 Paper::: {layout-nrow=2}:::### Fixed Prototype Pilot::: {layout-nrow=1}:::::::<br><br>### Comparison of Dot-Pattern Classification Studies:::: column-page-inset-right::: {#tbl-designs}| Study | **Hu & Nosofsky (2022)** | **Hu & Nosofsky (2024)** | **Fixed Prototype Pilot Study** ||-------------------------|---------------------------|---------------------------|----------------------------------|| **Publication** | *JEP: Learning, Memory, and Cognition* | *Memory & Cognition* | *(unpublished pilot study)* || **Participants** | - 89 Indiana University undergraduates<br>- Course credit participation<br>- Random assignment to conditions (REP or NREP)<br>- Normal or corrected vision | - 304 Indiana University students<br>- Random assignment to conditions (low, medium, high, or mixed distortion) | 146 IU Students || **Training Stage** | **Training Stage** | **Training Stage** | **Training Stage** || • **Procedure** | - **REP Condition:** 15 unique patterns (5 per category), repeated across 15 blocks (**225 trials total**)<br>- **NREP Condition:** 75 unique patterns (5 per category per block), no repetitions (**225 trials total**) | - 10 blocks, 27 trials each (**270 trials total**)<br>- Different set of training patterns in each block<br>- Corrective feedback for 2 seconds after each response | - Training patterns repeated across 10 blocks with randomized presentation order within each block<br>- Four between-subject conditions: low, medium, high, and mixed distortion levels || • **Stimuli** | - 15 or 75 unique dot patterns (depending on condition)<br>- Created using Posner (1967) procedure | - 270 unique training patterns <br>| - 27 unique dot patterns (9 per category)<br> || **Testing Stage** | **Transfer Phase** | **Testing Stage** | **Testing Stage** || • **Procedure** | - 63 trials total<br>- Random order of presentation | - 84 trials total<br>- Random order of presentation | - 87 trials total<br>- Random order of presentation || • **Stimuli** | - 15 old distortions (5 per category)<br>- 3 prototypes (one per category)<br>- 15 low-level distortions (5 per category)<br>- 15 new medium-level distortions (5 per category)<br>- 15 high-level distortions (5 per category) | - 27 old patterns from the training phase (9 per category)<br>- 3 prototypes (one per category)<br>- 9 new low-level distortions (3 per category)<br>- 18 new medium-level distortions (6 per category)<br>- 27 new high-level distortions (9 per category) | - 27 old distortions (9 per category)<br>- 3 prototypes (1 per category)<br>- 9 new low-level distortions (3 per category)<br>- 18 **Notes:**- **REP:** Repeating Protocol- **NREP:** Nonrepeating Protocol- **Hu & Nosofsky (2022)** investigated the effects of repeating vs. nonrepeating training patterns on category learning and generalization.- **Hu & Nosofsky (2024)** examined the impact of different training distortion levels on category learning and generalization. Each subject has unique prototype set. - **Fixed Prototype Pilot Study** examined the impact of different training distortion levels on category learning and generalization. Fixed set of prototypes across all subjects. - All studies used a dot pattern categorization paradigm where participants learned to classify patterns into categories based on visual similarity.- Dot pattern distortions were created using a modified Posner-Keele (1968) procedure. Low, medium and high distortions displaced the dots by an average of 4, 6, and 7.7 Posner-levels respectively.:::::::\pagebreak```{r}pacman::p_load(dplyr,purrr,tidyr,ggplot2,readr,here, patchwork, conflicted,ggh4x,gt)conflict_prefer_all("dplyr", quiet =TRUE)source(here::here("R/fun_plot.R"))lmc22 <-readRDS(here("data","lmc22.rds")) |>mutate(Pattern_Token =case_when( Pattern.Type =="Trained.Med"~"old", Pattern.Type2 =="Prototype"~"prototype", Pattern.Type2 =="New.Low"~"new_low", Pattern.Type2 =="New.Med"~"new_med", Pattern.Type2 =="New.High"~"new_high" )) |># set phase="Training" when Phase==1, and phase="Test" when Phase==2mutate(phase =case_when( Phase==1~"Training", Phase==2~"Test" ), Stage =case_when( Stage=="Med"~"Middle",TRUE~ Stage)) mc24 <-readRDS(here("data","mc24.rds"))fp24 <-readRDS(here("data","fixed_proto24.rds")) |>mutate(Stage =case_when( phase=="Test"~"Test",TRUE~ Stage )) all_data <- fp24 |>select(-pool_index) |>rbind(mc24) |>rbind(lmc22)all_data$Pattern_Token =factor(all_data$Pattern_Token,levels=c("old","prototype","new_low","new_med","new_high","special")) all_data$condit =factor(all_data$condit,levels=c("low","medium","mixed","high","nrep","rep"))all_data$exp =factor(all_data$exp,levels=c("lmc22","mc24","fixed_proto"))all_data$exp2 =factor(all_data$exp,labels=c("Hu & Nosofsky 2022","Hu & Nosofsky 2024","Fixed Prototype Pilot"))all_data$Stage =factor(all_data$Stage,levels=c("Start","Middle","End","Test"))all_data$phase =factor(all_data$phase,levels=c("Training","Test"))theme_set(theme_nice())yt <-round(seq(0,1,length.out=7), 2)xt <-seq(1,10,1)eg <-list(geom_hline(yintercept =c(.33, .66),linetype="dashed", alpha=.5),scale_y_continuous(breaks=yt,limits=c(0,1)),scale_x_continuous(breaks=xt))dtf <- all_data |>filter(Stage=="End") |>group_by(sbjCode, condit, Pattern_Token,exp2,Stage,Phase,phase) |>summarize(propCor=mean(Corr)) |>arrange(-propCor) |>group_by(exp2,condit) |># bin into quartile by propCormutate(quartile =ntile(propCor, 4), finalTrain=propCor) all_data <- all_data |>select(-quartile) |># remove original quartile varleft_join(dtf |>select(sbjCode,condit,quartile,exp2), by=c("sbjCode","condit","exp2"))html <-ifelse(knitr::pandoc_to() %in%c("html"), TRUE, FALSE)out_type <- knitr::opts_knit$get("rmarkdown.pandoc.to")if (html) {fw=11;rel_size=.70;} else {fw=8;rel_size=.5}print(fw)# Check trial totals# all_data |> filter(Phase==1) |> group_by(sbjCode,condit,exp) |> summarise(n=max(trial)) |> # group_by(condit,exp) |># distinct(n) |> arrange(exp)# all_data |> filter(Phase==2) |> group_by(sbjCode,condit,exp) |> summarise(nAll=max(trial),nTrain=min(trial)-1,n=nAll-nTrain) |> # group_by(condit,exp) |># distinct(n) |> arrange(exp)# all_data |> group_by(Phase,sbjCode,condit,exp) |> # summarise(n=n_distinct(trial)) |> # group_by(Phase,condit,exp) |> # distinct(n) |> # pivot_wider(names_from=Phase,values_from=n) |> # rename(nTrain=`1`,nTest=`2`) |> # arrange(exp)```## Training & Testing shown together- These plots show mean performance at the start, middle and end of training (first 3 points), and the testing performance for each item type (final 5 points). - The pilot study included "special" patterns, that were predicted to be more difficult. *click on plots to enlarge*:::: .smaller::: {.column-screen-inset-right}```{r}#| fig-width: !expr fw#| fig-height: !expr fw-2if(html) theme_set(theme_nice()) elsetheme_set(theme_nice_pdf())all_data |># filter(Pattern_Token != "special") |> group_by(sbjCode, condit, Pattern_Token,exp2,Stage,Phase,phase) |>summarize(Corr=mean(Corr)) |>group_by(condit,Pattern_Token,exp2,Stage,Phase,phase) |>summarise(empirical_stat =mean(Corr), sem =sd(Corr)/sqrt(length(Corr)),ci_lower =mean(Corr) - sem,ci_upper =mean(Corr) + sem) |>mutate(method ="standard error") |>ggplot(aes(x=interaction(Pattern_Token,Stage,phase), y=empirical_stat, col=condit, group=condit)) +geom_point(aes(shape=phase),size=2.5) +geom_line(aes(group = condit)) +geom_errorbar(aes(ymin = ci_lower, ymax = ci_upper),width=.3) +geom_vline(xintercept=c(3.5),linetype="dashed", alpha=.5) +facet_wrap(~exp2,scale="free_x") +labs(x="Item Type and Experiment Stage",y="Accuracy",col="Training Condition",title="Training & Testing Performance", subtitle="Training binned into 3 stages, and Testing Performance for each Item Type") +theme(ggh4x.axis.nestline =element_line(colour ="black"), axis.text.x =element_text(face ="plain", size =rel(rel_size))) +scale_x_discrete(guide ="axis_nested")```:::::: {.column-screen-inset-right}```{r}#| fig-width: !expr fw#| fig-height: !expr fw+1all_data |>#filter(Pattern_Token != "special") |> group_by(sbjCode, condit, Pattern_Token,exp2,Stage,Phase,phase,quartile) |>summarize(Corr=mean(Corr)) |>group_by(condit,Pattern_Token,exp2,Stage,Phase,phase,quartile) |>summarise(empirical_stat =mean(Corr), sem =sd(Corr)/sqrt(length(Corr)),ci_lower =mean(Corr) - sem,ci_upper =mean(Corr) + sem) |>mutate(method ="standard error",quartile=factor(quartile,levels=c("1","2","3","4"))) |>ggplot(aes(x=interaction(Pattern_Token,Stage,phase), y=empirical_stat, col=condit, group=condit)) +geom_point(aes(shape=phase),size=2.0) +geom_line(aes(group = condit)) +geom_errorbar(aes(ymin = ci_lower, ymax = ci_upper),width=.3) +geom_vline(xintercept=c(3.5),linetype="dashed", alpha=.5) +facet_wrap(exp2~quartile,scale="free_x") +labs(x="Item Type and Experiment Stage",y="Accuracy",col="Training Condition",title="Training & Testing Performance - Quartiles", subtitle="Training binned into 3 stages, and Testing Performance for each Item Type\nSplit into 4 quartiles based on end of training performance (1=worst; 4=best)") +theme(ggh4x.axis.nestline =element_line(colour ="black"),axis.text.x =element_text(face ="plain", size =rel(rel_size-.2))) +scale_x_discrete(guide ="axis_nested")```:::::::## Test Stage Comparisons::: {.panel-tabset}### Facet by experiment```{r}#| fig-width: 13#| fig-height: 11##| fig-cap: "lmc22: Hu & Nosofsky 2022; mc24: Hu & Nosofsky 2024; fixed_proto: Fixed Prototype Pilot Study"#if(html) theme_set(theme_nice_b()) else theme_set(theme_minimal())#theme_set(theme_minimal())all_data |>filter(Phase==2, Pattern_Token !="special") |>group_by(sbjCode, condit, Pattern_Token,exp2) |>summarize(Corr=mean(Corr)) |>group_by(condit,Pattern_Token,exp2) |>summarise(empirical_stat =mean(Corr), sem =sd(Corr)/sqrt(length(Corr)),ci_lower =mean(Corr) - sem,ci_upper =mean(Corr) + sem) |>mutate(method ="standard error") |>ggplot(aes(x=Pattern_Token, y=empirical_stat, col=condit, group=condit)) +geom_point() +geom_line(aes(group = condit)) +geom_errorbar(aes(ymin = ci_lower, ymax = ci_upper)) +labs(x="Item Type",y="Accuracy",col="Training Condition",title="Testing Performance") +facet_wrap(~exp2)```### Facet by item type```{r}#| fig-width: 13#| fig-height: 11all_data |>filter(Phase==2, Pattern_Token !="special") |>group_by(sbjCode, condit, Pattern_Token,exp2) |>summarize(Corr=mean(Corr)) |>group_by(condit,Pattern_Token,exp2) |>summarise(empirical_stat =mean(Corr), sem =sd(Corr)/sqrt(length(Corr)),ci_lower =mean(Corr) - sem,ci_upper =mean(Corr) + sem) |>mutate(method ="standard error") |>ggplot(aes(x=condit, y=empirical_stat, col=exp2, group=exp2)) +geom_point() +geom_line(aes(group = exp2)) +geom_errorbar(aes(ymin = ci_lower, ymax = ci_upper)) +facet_wrap(~Pattern_Token) +labs(x="Training Condition",y="Accuracy",col="Study",title="Testing Performance") ```### Facet by train group```{r}#| fig-width: 13#| fig-height: 11all_data |>filter(Phase==2, Pattern_Token !="special") |>group_by(sbjCode, condit, Pattern_Token,exp2) |>summarize(Corr=mean(Corr)) |>group_by(condit,Pattern_Token,exp2) |>summarise(empirical_stat =mean(Corr), sem =sd(Corr)/sqrt(length(Corr)),ci_lower =mean(Corr) - sem,ci_upper =mean(Corr) + sem) |>mutate(method ="standard error") |>ggplot(aes(x=Pattern_Token, y=empirical_stat, col=exp2, group=exp2)) +geom_point() +geom_line(aes(group = exp2)) +geom_errorbar(aes(ymin = ci_lower, ymax = ci_upper)) +facet_wrap(~condit) +labs(x="Item Type",y="Accuracy",col="Study",title="Testing Performance") ```:::## Training Stage Comparisons::: {.panel-tabset}### Facet by Exp```{r}#| fig-width: 12#| fig-height: 10nbins=10all_data |>filter(Phase==1) |>group_by(sbjCode, condit,exp2) |>mutate(nTrain=max(trial),train_bin =cut(trial,breaks=seq(1,max(trial),length.out=nbins+1),include.lowest=TRUE,labels=FALSE)) |>group_by(sbjCode,train_bin, condit,exp2) |>summarize(Corr=mean(Corr),.groups="keep") |>ggplot(aes(x=train_bin,y=Corr,fill=condit,col=condit)) +stat_summary(geom="line",fun=mean)+stat_summary(geom="errorbar",fun.data=mean_se) +facet_wrap(~exp2,scales="free_x") +labs(title="Training - All Sbjs.", y="Accuracy",col="Training Condition", x="Trial Bin",subtitle="Training accuracy - 10 bins") +scale_x_continuous(breaks=seq(1,nbins)) +scale_y_continuous(breaks=round(seq(0,1,length.out=7), 2)) +geom_hline(yintercept =c(.33, .66),linetype="dashed", alpha=.5)```*click on plots to enlarge*::: {.column-page-right}```{r}#| fig-width: !expr fw#| fig-height: !expr fw-1#| nbins=10grp_avg <- all_data |>filter(Phase==1) |>group_by(sbjCode, condit,exp2) |>mutate(nTrain=max(trial),train_bin =cut(trial,breaks=seq(1,max(trial),length.out=nbins+1),include.lowest=TRUE,labels=FALSE)) |>group_by(sbjCode,train_bin, condit,exp2) |>summarize(Corr=mean(Corr),.groups="keep") design <-" AB## CDEF HIJK"all_data |>filter(Phase==1) |>group_by(sbjCode, condit,exp2) |>mutate(nTrain=max(trial),train_bin =cut(trial,breaks=seq(1,max(trial),length.out=nbins+1),include.lowest=TRUE,labels=FALSE)) |>group_by(sbjCode,train_bin, condit,exp2) |>summarize(Corr=mean(Corr),.groups="keep") |>ggplot(aes(x=train_bin,y=Corr,group=sbjCode,fill=condit,col=condit)) +stat_summary(geom="line",fun=mean)+stat_summary(geom="errorbar",fun.data=mean_se) +# geom_line(data=grp_avg,aes(x=train_bin,y=Corr,group=condit),color="black") +stat_summary(data=grp_avg,aes(x=train_bin,y=Corr,group=condit),geom="line",fun=mean,color="black",size=1.2)+stat_summary(data=grp_avg,aes(x=train_bin,y=Corr,group=condit),geom="errorbar",fun.data=mean_se,color="black",width=.4)+#facet_grid2(vars(exp2), vars(condit), render_empty = FALSE)+#facet_nested(~exp2+condit,scales="free_x") +# facet_nested_wrap(~exp2+condit,scales="free_x") +facet_manual(~exp2+condit, design = design) +#facet_wrap(exp2~condit,scales="free_x") +labs(title="Training - individual learning curves.", y="Accuracy",col="Training Condition", x="Trial Bin",subtitle="Training accuracy - each line is an individual sbj.\n Black lines are group averages") +scale_x_continuous(breaks=seq(1,nbins)) +scale_y_continuous(breaks=round(seq(0,1,length.out=7), 2)) +geom_hline(yintercept =c(.33, .66),linetype="dashed", alpha=.5)```:::### Original Blocks- Hu & Nosofsky 2022 had 15 blocks of 15 trials each - 225 trials total- Hu & Nosofsky 2024 & Fixed Prototype pilot each had 10 blocks of 27 trials each - 270 trials total```{r}#| fig-width: 12#| fig-height: 10###| layout-ncol: 2 all_data |>filter(Phase==1) |>group_by(sbjCode, condit, Pattern_Token,Block,exp2) |>summarize(Corr=mean(Corr),.groups="keep") |>ggplot(aes(x=Block, y=Corr, color=interaction(exp2,condit))) +stat_summary(geom="line",fun=mean)+stat_summary(geom="errorbar", fun.data=mean_se,width=.1) +labs(title="Training Performance - All Sbjs.", y="Accuracy") +#eg + theme(legend.position ="top") +list(geom_hline(yintercept =c(.33, .66),linetype="dashed", alpha=.5),scale_y_continuous(breaks=yt,limits=c(0,1)),scale_x_continuous(breaks=seq(1:15)))```### Bin into equal sized blocks```{r}#| fig-width: 12#| fig-height: 10###| layout-ncol: 2 nbins=10all_data |>filter(Phase==1) |>group_by(sbjCode, condit,exp2) |>mutate(nTrain=max(trial),train_bin =cut(trial,breaks=seq(1,max(trial),length.out=nbins+1),include.lowest=TRUE,labels=FALSE)) |>group_by(sbjCode,train_bin, condit,exp) |>summarize(Corr=mean(Corr),.groups="keep") |>ggplot(aes(x=train_bin, y=Corr, color=interaction(exp,condit))) +stat_summary(geom="line",fun=mean)+stat_summary(geom="errorbar", fun.data=mean_se,width=.1) +labs(title="Training Performance - All Sbjs.", y="Accuracy") +#eg + theme(legend.position ="top") +list(geom_hline(yintercept =c(.33, .66),linetype="dashed", alpha=.5),scale_y_continuous(breaks=yt,limits=c(0,1)),scale_x_continuous(breaks=seq(1:15)))```::: <!-- ::: {.panel-tabset} --><!-- ### p1 -->```{r}#| eval: false##| layout-ncol: 2 all_data |>filter(Phase==2, Pattern_Token !="special") |>group_by(sbjCode, condit, Pattern_Token,exp) |>summarize(Corr=mean(Corr)) |>group_by(sbjCode,condit,Pattern_Token,exp) |>mutate(method ="standard error") |>ggplot(aes(x=Pattern_Token, y=Corr, col=condit, group=sbjCode)) +geom_point() +geom_line(aes(group = sbjCode)) +labs(x="Item Type",y="Accuracy",col="Training Condition") +facet_wrap(condit~exp)all_data |>group_by(sbjCode, condit, Pattern_Token,exp2,Stage,Phase) |>summarize(Corr=mean(Corr)) |>group_by(condit,Pattern_Token,exp2,Stage,Phase) |>summarise(empirical_stat =mean(Corr), sem =sd(Corr)/sqrt(length(Corr)),ci_lower =mean(Corr) - sem,ci_upper =mean(Corr) + sem) |>mutate(method ="standard error") |>ggplot(aes(x=Stage, y=empirical_stat, col=Pattern_Token, group=Pattern_Token)) +geom_point() +geom_line(aes(group = Pattern_Token)) +geom_errorbar(aes(ymin = ci_lower, ymax = ci_upper),width=.3) +facet_wrap(exp2~condit,scale="free_x") +labs(x="Training Condition",y="Accuracy",col="Item Type",title="Testing Performance") fp24 |>filter(Phase==2) |>group_by(sbjCode, condit, Pattern_Token) |>summarize(Corr=mean(Corr)) |>ggplot(aes(x=Pattern_Token, y=Corr, fill=condit, group=condit)) +stat_summary(geom="bar",fun=mean, position=position_dodge())+stat_summary(geom="errorbar", fun.data=mean_se, position=position_dodge()) +labs(title="Testing Performance - All Sbjs.", y="Accuracy") fp24 |>filter(Phase==2) |>group_by(sbjCode, condit, Pattern_Token) |>summarize(Corr=mean(Corr)) |>ggplot(aes(x=condit, y=Corr, fill=Pattern_Token, group=Pattern_Token)) +stat_summary(geom="bar",fun=mean, position=position_dodge())+stat_summary(geom="errorbar", fun.data=mean_se, position=position_dodge()) +labs(title="Testing Performance - All Sbjs.", y="Accuracy") fp24 |>filter(Phase==1) |>group_by(sbjCode, condit, Pattern_Token,Block) |>summarize(Corr=mean(Corr),.groups="keep") |>ggplot(aes(x=Block, y=Corr, col=condit, group=condit)) +stat_summary(geom="line",fun=mean)+stat_summary(geom="errorbar", fun.data=mean_se,width=.1) +labs(title="Testing Performance - All Sbjs.", y="Accuracy") +#eg + theme(legend.position ="top") + eglmc22 |>filter(Phase==2) |>group_by(sbjCode, condit, Pattern_Token) |>summarize(Corr=mean(Corr)) |>ggplot(aes(x=condit, y=Corr, fill=Pattern_Token, group=Pattern_Token)) +stat_summary(geom="bar",fun=mean, position=position_dodge())+stat_summary(geom="errorbar", fun.data=mean_se, position=position_dodge()) +labs(title="Testing Performance - All Sbjs.", y="Accuracy") ```<!-- ### p2 -->```{r}#| eval: false#| fig-width: 11#| fig-height: 13#| layout-ncol: 2 #| fig-cap: #| - "Line Plot 1"#| - "Line Plot 2"#| - "Line Plot 4"#| - "Line Plot 5"all_data |>filter(Phase==2) |>group_by(sbjCode, condit, Pattern_Token,exp2) |>summarize(Corr=mean(Corr)) |>group_by(condit,Pattern_Token,exp2) |>summarise(empirical_stat =mean(Corr), sem =sd(Corr)/sqrt(length(Corr)),ci_lower =mean(Corr) - sem,ci_upper =mean(Corr) + sem) |>mutate(method ="standard error") |>ggplot(aes(x=condit, y=empirical_stat, col=Pattern_Token, group=Pattern_Token)) +geom_point() +geom_line(aes(group = Pattern_Token)) +geom_errorbar(aes(ymin = ci_lower, ymax = ci_upper),width=.3) +facet_wrap(~exp2,scale="free_x") +labs(x="Training Condition",y="Accuracy",col="Item Type",title="Testing Performance") all_data |>filter(Phase==2) |>group_by(sbjCode, condit, Pattern_Token) |>summarize(Corr=mean(Corr)) |>ggplot(aes(x=condit, y=Corr, fill=Pattern_Token, group=Pattern_Token)) +stat_summary(geom="bar",fun=mean, position=position_dodge())+stat_summary(geom="errorbar", fun.data=mean_se, position=position_dodge()) +labs(title="Testing Performance - All Sbjs.", y="Accuracy") all_data |>filter(Phase==2) |>group_by(sbjCode, condit, Pattern_Token,exp) |>summarize(Corr=mean(Corr)) |>ggplot(aes(x=condit, y=Corr, fill=Pattern_Token, group=Pattern_Token)) +stat_summary(geom="bar",fun=mean, position=position_dodge())+stat_summary(geom="errorbar", fun.data=mean_se, position=position_dodge()) +facet_wrap(~exp,scales="free_x") +labs(title="Testing Performance - All Sbjs.", y="Accuracy") all_data |>filter(Phase==2) |>group_by(sbjCode, condit, Pattern_Token,exp) |>summarize(Corr=mean(Corr)) |>ggplot(aes(x=exp, y=Corr, fill=Pattern_Token, group=Pattern_Token)) +stat_summary(geom="bar",fun=mean, position=position_dodge())+stat_summary(geom="errorbar", fun.data=mean_se, position=position_dodge()) +facet_wrap(~condit,scales="free_x") +labs(title="Testing Performance - All Sbjs.", y="Accuracy") all_data |>filter(Phase==2) |>group_by(sbjCode, condit, Pattern_Token,exp) |>summarize(Corr=mean(Corr)) |>ggplot(aes(x=condit, y=Corr, fill=exp, group=exp)) +stat_summary(geom="bar",fun=mean, position=position_dodge())+stat_summary(geom="errorbar", fun.data=mean_se, position=position_dodge()) +facet_wrap(~Pattern_Token,scales="free_x") +labs(title="Testing Performance - All Sbjs.", y="Accuracy") ```<!-- ::: -->```{r}library(stringr)final_data <- all_data |>filter(Pattern_Token !="special", Phase ==2) |>group_by(sbjCode, condit, Pattern_Token, exp2, Stage, Phase, phase) |>summarize(Corr =mean(Corr), .groups ="drop") |>group_by(condit, Pattern_Token, exp2, Stage, Phase, phase) |>summarise(empirical_stat =mean(Corr), sem =sd(Corr) /sqrt(n()),ci_lower =mean(Corr) - sem,ci_upper =mean(Corr) + sem,.groups ="drop") |>mutate(mean_sem =paste0(round(empirical_stat, 2), " (", round(sem, 3), ")"),method ="standard error") |>select(condit, Pattern_Token, exp2, phase, mean_sem)# Reshape data to wide format for gt tablefinal_data_wide <- final_data |>pivot_wider(names_from = Pattern_Token, values_from = mean_sem) |>arrange(exp2) # Identify the row indices with the maximum value in each Pattern_Token column within each level of Experimentmax_indices <- final_data_wide |>group_by(exp2) |>summarise(across(starts_with("old") |starts_with("prototype") |starts_with("new_low") |starts_with("new_med") |starts_with("new_high"), ~which.max(as.numeric(str_extract(., "^\\d+\\.\\d+"))))) |>pivot_longer(-exp2, names_to ="column", values_to ="row")# Create the gt tablegt_table <- final_data_wide |>gt() |>tab_header(title ="Testing Phase Performance Summary",subtitle ="Mean (SE) for Each Item Type and Condition" ) |>cols_label(condit ="Condition",exp2 ="Experiment",phase ="Phase",old ="Old",prototype ="Prototype",new_low ="New Low",new_med ="New Medium",new_high ="New High" ) |>cols_align(align ="center",columns =everything() ) |>tab_footnote(footnote ="For each experiment, the row with the highest value for each item type is bolded" )# Convert exp2 to character for comparisonfinal_data_wide <- final_data_wide |>mutate(exp2 =as.character(exp2))max_indices <- max_indices |>mutate(exp2 =as.character(exp2))# Apply bolding to cells with the maximum valuesfor (i inseq_len(nrow(max_indices))) { gt_table <- gt_table |>tab_style(style =cell_text(weight ="bold"),locations =cells_body(columns =all_of(max_indices$column[i]),rows =which(final_data_wide$exp2 == max_indices$exp2[i])[max_indices$row[i]] ) )}# Add darker row borders dividing the experimentsexperiment_levels <-unique(final_data_wide$exp2)row_indices <-which(final_data_wide$exp2 != dplyr::lag(final_data_wide$exp2, default =first(final_data_wide$exp2)))for (row_index in row_indices) { gt_table <- gt_table |>tab_style(style =cell_borders(sides ="top",color ="black",weight =px(2) ),locations =cells_body(rows = row_index ) )}# Print the tablegt_table```\normalsize## References::: {#refs}:::