avg_set_rating<-setCounts2|>summarise("Avg Ratings Per Set"=mean(n))|>pull(1)d|>summarize("N Subjects"=n_distinct(sbjCode), "N Prototype Sets"=n_distinct(set))|>mutate("Avg Ratings Per Set"=avg_set_rating)|>kbl()
Table 1: Current counts of unique subjects, and prototype sets
N Subjects
N Prototype Sets
Avg Ratings Per Set
87
304
29
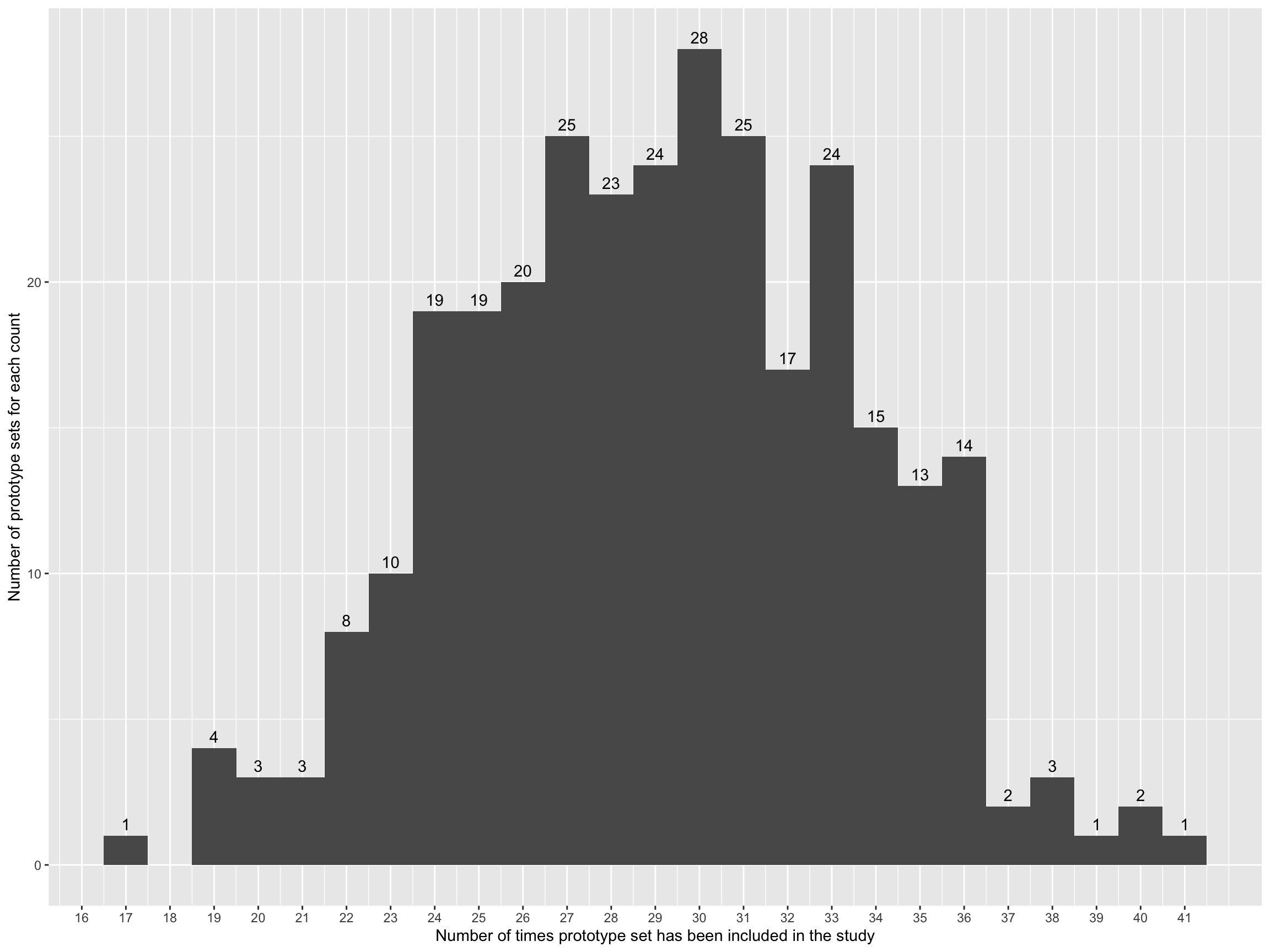
Prototype set counts
Display code
setCounts2|>group_by(n)|>summarise(nc=n())|>rename("Number of times prototype set has been included in the study"=n, "Number of prototype sets with this count"=nc)|>gt()|>tab_spanner(label ="Prototype Set Counts")|>tab_header(title ="Prototype Set Counts")|>tab_source_note("Note: The number of times a prototype set has been included in the study is equal to the number of participants who rated the set.")
Prototype Set Counts
Number of times prototype set has been included in the study
Number of prototype sets with this count
17
1
19
4
20
3
21
3
22
8
23
10
24
19
25
19
26
20
27
25
28
23
29
24
30
28
31
25
32
17
33
24
34
15
35
13
36
14
37
2
38
3
39
1
40
2
41
1
Note: The number of times a prototype set has been included in the study is equal to the number of participants who rated the set.
Display code
# d |> filter(sbjCode==11) |> select(sbjCode,date,trial,pair_label,set,rt,time_elapsed,time)# d |> group_by(sbjCode,set) |> # summarize (n=n()) |># gt()#d |> group_by(sbjCode, item_label_1, item_label_2) |> summarise(n=n())# (1-.33)^8# (factorial(8)/(factorial(6)*factorial(8-6))) * (.33^6)*((1-.33)^(8-6))# (factorial(8)/(factorial(7)*factorial(8-7))) *(.33^6)*((1-.33)^(8-7))# (factorial(8)/(factorial(8)*factorial(8-8))) *(.33^6)*(1-.33)^(8-8)# d |> pivot_longer(cols=c(item_label_1, item_label_2), names_to="item_label", values_to="item") |> # group_by(sbjCode, item) |> summarise(n=n())# patternCounts <- d |> pivot_longer(cols=c(item_label_1, item_label_2), names_to="item_label", values_to="item") |> # group_by(item) |> summarise(n=n(),resp=mean(response),sd=sd(response)) |> arrange(desc(n))# d |> # pivot_longer(cols=c(item_label_1, item_label_2), names_to="item_label", values_to="item") |> select(sbjCode,set,pair_label,item_label,item,response) |> group_by(set) |># summarize(n=n_distinct(sbjCode)) |> arrange(desc(n)) # d |> group_by(sbjCode, file) |> summarise(n=n())# d |> group_by(sbjCode, set) |> summarise(n=n())# d |> group_by(sbjCode) |> summarise(n_distinct(file))# d |> group_by(sbjCode) |> summarise(n_distinct(set))# sp <- setCounts2 |> # mutate(set=reorder(set,n)) |># ggplot(aes(x=set,y=n)) +# geom_col() +# theme(legend.title=element_blank(),# axis.text.x = element_text(size=5,angle = 90, hjust = 0.5, vjust = 0.5)) +# labs(x="Prototype Set", y="Number of Participants to rate set") sh<-setCounts2|>ggplot(aes(x=n))+geom_histogram(binwidth =1)+scale_x_continuous(breaks=seq(0, max(setCounts2$n), by =1))+geom_text(stat="count", aes(label=..count..), vjust=-0.5)+labs(x="Number of times prototype set has been included in the study", y="Number of prototype sets for each count")#sp/shsh
Prototype set counts
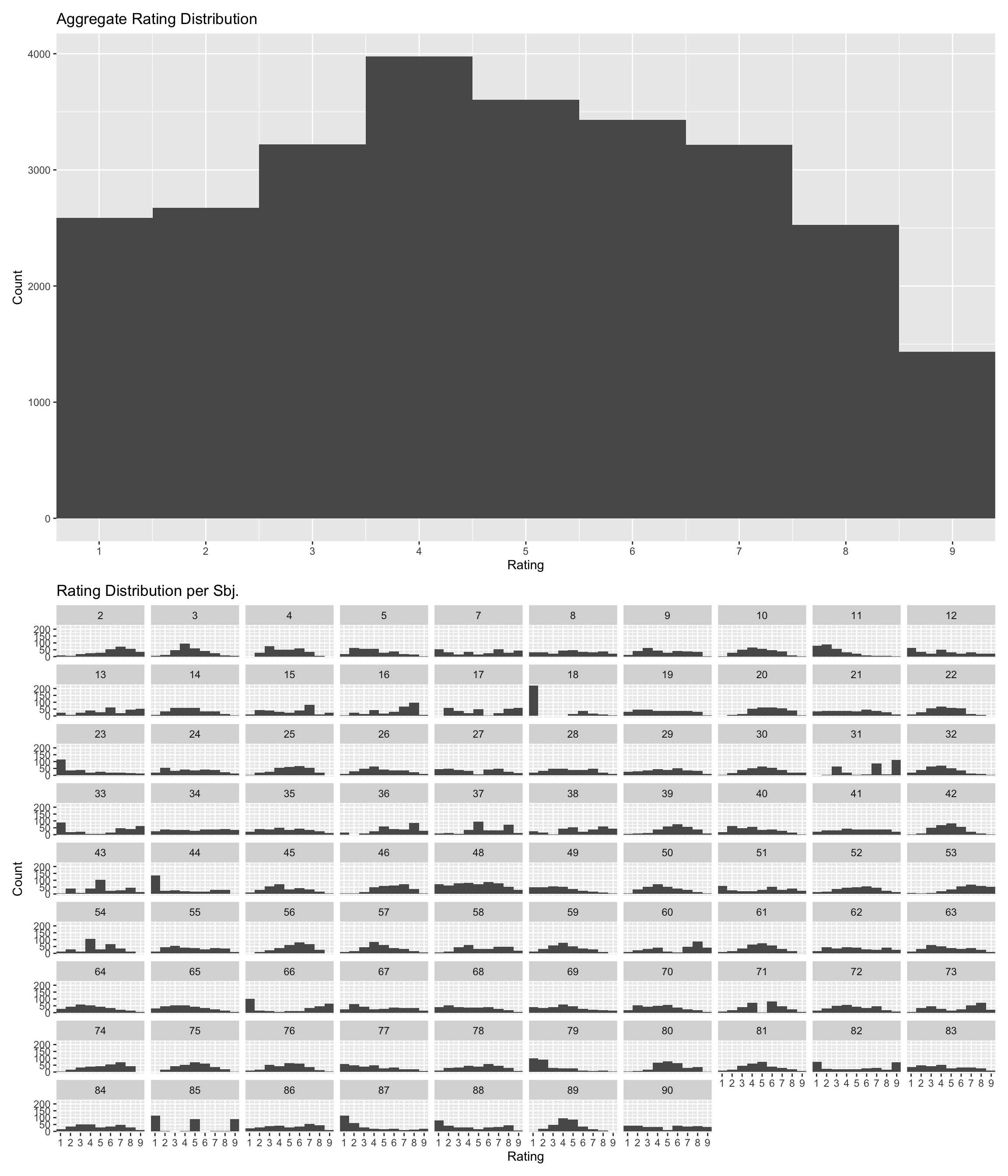
Rating Distributions
Display code
pgr<-d|>ggplot(aes(x=response))+geom_histogram(binwidth=1)+scale_x_continuous(breaks=seq(1, 9, by =1))+coord_cartesian(xlim =c(1, 9))+labs(title="Aggregate Rating Distribution", x="Rating", y="Count")pir<-d|>ggplot(aes(x=response))+geom_histogram(binwidth=1)+facet_wrap(~sbjCode)+scale_x_continuous(breaks=seq(1, 9, by =1))+coord_cartesian(xlim =c(1, 9))+labs(title="Rating Distribution per Sbj.", x="Rating", y="Count")pgr/pir
Rating distributions
Reaction Time Distributions
Display code
prtg<-d|>ggplot(aes(x=rt))+geom_density()+labs(title="Aggregate Reaction Time Distribution", x="Reaction Time (ms)", y="Density")prtid<-d|>ggplot(aes(x=rt))+geom_density()+facet_wrap(~sbjCode,scale="free_x")+labs(title="Reaction Time Distribution per Sbj.", x="Reaction Time (ms)", y="Density")prtg/prtid
d%>%filter(pair_label%in%{pairCounts|>filter(n>=min_resp)|>slice_max(mean_resp,n=n_show, with_ties=FALSE)|>pull(pair_label)})|>group_by(pair_label)|>slice_head(n=1)%>%plot_dotsAll()+plot_annotation(title=glue::glue("Highest rated pairs ( out of sets with n>={min_resp} ratings)"), theme =theme(plot.title =element_text(hjust =0.4)))
Pattern Pair Table
All pairs with >=25 ratings
click on column headers to change sort order
e.g. clicking on “Mean Rating” will toggle showing the pairs rated most similar or most dissimilar
clicking on “SD” will toggle showing the pairs with the most or least agreement in ratings
note your screen may need to be at full width to see all columns
Table 3: Example of how data is structure after combining similarity ratings with CatLearn accuracy. 5 Pattern types * 3 Categories = 15 rows per subject in the 2024 study
Table 4: Example of how data is structure after combining similarity ratings with CatLearn accuracy. 5 Pattern types * 3 Categories = 15 rows per subject in the 2024 study
Source Code
---title: Dot Pattern Ratings - data checksdate: last-modifiedlightbox: truealiases: - /dotSim_Analysis.htmlformat: html: grid: sidebar-width: 220px body-width: 1200px margin-width: 170px gutter-width: 1.0remtoc: falsepage-layout: fulltoc-depth: 3code-fold: showcode-tools: trueimage: /assets/dots1.pngexecute: warning: false eval: true---- catLearn accuracy refers to accuracy on the categorization task in the Hu & Nosofsky 2024 study.- prototype sets refer to sets of 3 prototypes that correspond to a single participant in the Hu & Nosofsky 2024 study. - prototype pairs refer to the specific pairs of prototypes that are displayed together on a rating trial (3 pairs per set). ```{r}pacman::p_load(dplyr,purrr,tidyr,ggplot2, here, patchwork, conflicted, jsonlite,stringr, gt, knitr, kableExtra, lubridate,ggh4x, lmerTest)walk(c("dplyr", "lmerTest"), conflict_prefer_all, quiet =TRUE)options(digits=2, scipen=999, dplyr.summarise.inform=FALSE)walk(c("fun_plot"), ~source(here::here(paste0("R/", .x, ".R"))))mc24_proto <-read.csv(here("Stimulii","mc24_prototypes.csv")) |>mutate(set=paste0(sbjCode,"_",condit)) sbj_cat <-read.csv(here("data","mc24_sbj_cat.csv"))dfiles <-list(path=list.files(here::here("data/dotSim_data"),full.names=TRUE))d <-map_dfr(dfiles$path, ~read.csv(.x))d <-map_dfr(dfiles$path, ~{read.csv(.x) |>mutate(sfile=tools::file_path_sans_ext(basename(.x)))}) |>select(-trial_index, -internal_node_id,-trial_type) |>mutate(set =paste(str_extract(item_label_1, "^\\d+"),str_extract(item_label_1, "[a-z]+"), sep ="_")) |>mutate(pair_label =paste0(item_label_1,"_",item_label_2)) |>relocate(sbjCode,date,set,pair_label,trial,item_label_1,item_label_2,response,rt)setCounts <- d |>pivot_longer(cols=c(item_label_1, item_label_2), names_to="item_label", values_to="item") |>group_by(set) |>summarise(n=n_distinct(sbjCode),resp=mean(response),sd=sd(response)) |>arrange(desc(n))# length(unique(mc_proto$set)) # 304setCounts2 <- mc24_proto |>group_by(set) |>slice_head(n=1) |>select(id,file,set) |>left_join(setCounts,by="set") |>mutate(n =ifelse(is.na(n), 0, n), .groups="drop") |>arrange(n) |>ungroup()pairCounts <- d |>group_by(pair_label,set) |>summarise(n=n(),mean_resp=mean(response),sd=sd(response)) |>arrange(desc(n)) |>ungroup()patternAvg <- d |>pivot_longer(cols=c(item_label_1, item_label_2), names_to="item_label", values_to="item") |>group_by(item,file) |>summarise(n_rating=n(),resp=mean(response),sd=sd(response)) |>arrange(desc(n_rating))cat_sim <- sbj_cat |>mutate(item=item_label) |>left_join(patternAvg,by=c("file","item")) |>arrange(desc(n_rating)) |>#remove rows where n_rating is NA, or less than 4filter(!is.na(n_rating),n_rating>=12) |>mutate(sim_group =ifelse(resp>6.0,"Very Similar",ifelse(resp<3.5,"Very Dissimilar","Medium"))) |>mutate(sim_group=factor(sim_group,levels=c("Very Dissimilar","Medium","Very Similar"))) cat_sim_test <- cat_sim |>filter(Phase==2) |>group_by(condit) |>mutate(quartile=ntile(Corr,4))#cor(cat_sim$resp,cat_sim$Corr)# m1 <- lmer(Corr ~ resp + (1|sbjCode), data=cat_sim)# summary(m1)# m1 <- lmer(Corr ~ resp + (1|Pattern.Type) + (1|sbjCode), data=cat_sim)# summary(m1)# m1 <- lmer(Corr ~ resp*Pattern.Type*condit + (1|sbjCode), data=cat_sim)# summary(m1)# m1 <- lmer(Corr ~ sim_group + (1|sbjCode), data=cat_sim)# summary(m1)# m1 <- lmer(Corr ~ sim_group*condit + (1|sbjCode), data=cat_sim)# summary(m1)# m1 <- lmer(Corr ~ sim_group*condit*Pattern.Type + (1|sbjCode), data=cat_sim)# summary(m1)```## Data Inspection & Sanity Checks```{r}#| label: tbl-totals#| tbl-cap: "Current counts of unique subjects, and prototype sets"avg_set_rating <- setCounts2 |>summarise("Avg Ratings Per Set"=mean(n)) |>pull(1)d |>summarize("N Subjects"=n_distinct(sbjCode), "N Prototype Sets"=n_distinct(set)) |>mutate("Avg Ratings Per Set"= avg_set_rating) |>kbl()```### Prototype set counts\ \```{r}setCounts2 |>group_by(n) |>summarise(nc=n()) |>rename("Number of times prototype set has been included in the study"=n, "Number of prototype sets with this count"=nc) |>gt() |>tab_spanner(label ="Prototype Set Counts") |>tab_header(title ="Prototype Set Counts") |>tab_source_note("Note: The number of times a prototype set has been included in the study is equal to the number of participants who rated the set." )``````{r}#| fig-cap: Prototype set counts#| fig-width: 12#| fig-height: 9# d |> filter(sbjCode==11) |> select(sbjCode,date,trial,pair_label,set,rt,time_elapsed,time)# d |> group_by(sbjCode,set) |> # summarize (n=n()) |># gt()#d |> group_by(sbjCode, item_label_1, item_label_2) |> summarise(n=n())# (1-.33)^8# (factorial(8)/(factorial(6)*factorial(8-6))) * (.33^6)*((1-.33)^(8-6))# (factorial(8)/(factorial(7)*factorial(8-7))) *(.33^6)*((1-.33)^(8-7))# (factorial(8)/(factorial(8)*factorial(8-8))) *(.33^6)*(1-.33)^(8-8)# d |> pivot_longer(cols=c(item_label_1, item_label_2), names_to="item_label", values_to="item") |> # group_by(sbjCode, item) |> summarise(n=n())# patternCounts <- d |> pivot_longer(cols=c(item_label_1, item_label_2), names_to="item_label", values_to="item") |> # group_by(item) |> summarise(n=n(),resp=mean(response),sd=sd(response)) |> arrange(desc(n))# d |> # pivot_longer(cols=c(item_label_1, item_label_2), names_to="item_label", values_to="item") |> select(sbjCode,set,pair_label,item_label,item,response) |> group_by(set) |># summarize(n=n_distinct(sbjCode)) |> arrange(desc(n)) # d |> group_by(sbjCode, file) |> summarise(n=n())# d |> group_by(sbjCode, set) |> summarise(n=n())# d |> group_by(sbjCode) |> summarise(n_distinct(file))# d |> group_by(sbjCode) |> summarise(n_distinct(set))# sp <- setCounts2 |> # mutate(set=reorder(set,n)) |># ggplot(aes(x=set,y=n)) +# geom_col() +# theme(legend.title=element_blank(),# axis.text.x = element_text(size=5,angle = 90, hjust = 0.5, vjust = 0.5)) +# labs(x="Prototype Set", y="Number of Participants to rate set") sh <- setCounts2 |>ggplot(aes(x=n)) +geom_histogram(binwidth =1) +scale_x_continuous(breaks=seq(0, max(setCounts2$n), by =1)) +geom_text(stat="count", aes(label=..count..), vjust=-0.5) +labs(x="Number of times prototype set has been included in the study", y="Number of prototype sets for each count") #sp/shsh```\ \### Rating Distributions```{r}#| fig-cap: Rating distributions#| fig-width: 12#| fig-height: 14pgr <- d |>ggplot(aes(x=response))+geom_histogram(binwidth=1) +scale_x_continuous(breaks=seq(1, 9, by =1)) +coord_cartesian(xlim =c(1, 9)) +labs(title="Aggregate Rating Distribution", x="Rating", y="Count") pir <- d |>ggplot(aes(x=response))+geom_histogram(binwidth=1) +facet_wrap(~sbjCode) +scale_x_continuous(breaks=seq(1, 9, by =1)) +coord_cartesian(xlim =c(1, 9)) +labs(title="Rating Distribution per Sbj.", x="Rating", y="Count") pgr/pir```### Reaction Time Distributions```{r}#| fig-cap: Reaction time distributions#| fig-width: 12#| fig-height: 14prtg <- d |>ggplot(aes(x=rt))+geom_density() +labs(title="Aggregate Reaction Time Distribution", x="Reaction Time (ms)", y="Density")prtid <- d |>ggplot(aes(x=rt))+geom_density() +facet_wrap(~sbjCode,scale="free_x") +labs(title="Reaction Time Distribution per Sbj.", x="Reaction Time (ms)", y="Density")prtg/prtid```### Individual Subject Ratings```{r}#| label: tbl-indv-sbj#| tbl-cap: "Individual Subject Ratings "# d |> summarize(n=n(), n_distinct(sbjCode), n_distinct(file), n_distinct(set), n_distinct(trial), n_distinct(item_label_1), n_distinct(item_label_2))# d %>%# filter(sbjCode == 11) %>%# select(sbjCode, date, trial, set, rt, time) %>%# mutate(time_parsed = parse_date_time(paste(date, time), orders = c("mdY IMS p", "mdy IMS p"))) %>%# group_by(sbjCode, date) %>%# summarise(start_time = min(time_parsed), end_time = max(time_parsed)) %>%# mutate(endTimeMinusStart = end_time - start_time)plot_hist_sbj <-function(id) { d |>filter(sbjCode==id) |>ggplot(aes(x = response)) +geom_histogram(binwidth=1,fill ='dodgerblue4') +scale_x_continuous(breaks=seq(1, 9, by =1)) +coord_cartesian(xlim =c(1, 9)) +theme_minimal() +theme(axis.title.x=element_blank(),axis.title.y=element_blank(),axis.text.x=element_text(size=26)) }sbj_sum <- d |>group_by(sbjCode) |>#filter(sbjCode<5) |>mutate(time_parsed =parse_date_time(paste(date, time), orders =c("mdY IMS p", "mdy IMS p"))) |>summarize ("Mean Rating"=mean(response),"SD Rating"=sd(response), "Mean RT"=mean(rt)/1000, #"Total Time (min)" = max(time_elapsed)/60000,"Total Time (min)"=round(difftime(max(time_parsed), min(time_parsed), units ="mins"),1),n_prototype_sets =n_distinct(set), "N Trials"=n_distinct(trial)) |>mutate("Response_Distribution"=sbjCode) sbj_sum |>gt() |>text_transform(locations =cells_body(columns ='Response_Distribution'),fn =function(column) {map(column, plot_hist_sbj) |>ggplot_image(height =px(80), aspect_ratio =3) } )sbj_sum |>mutate(total_time=as.numeric(`Total Time (min)`)) |>rename("Subject"=sbjCode, "N_Sets"= n_prototype_sets) |>summarize("Median Completition time (min)"=median(total_time), "Average Completion Time"=mean(total_time), "Min Completion Time (min)"=min(total_time), "Max Completion Time (min)"=max(total_time)) |>kbl()```## Lowest and Highest Rated Pairs```{r}#| fig-width: 11#| fig-height: 9# patternCounts |> filter(n>=8) |> slice_min(resp)# patternCounts |> filter(n>=8) |> slice_max(resp)# setCounts |> filter(n>=24) |> slice_min(resp)# setCounts |> filter(n>=24) |> slice_max(resp)# pairCounts |> filter(n>=5) |> slice_min(resp,n=2)# pairCounts |> filter(n>=5) |> slice_max(resp)min_resp=7n_show=3d %>%filter(pair_label %in% {pairCounts |>filter(n>=min_resp) |>slice_min(mean_resp,n=n_show, with_ties=FALSE) |>pull(pair_label)} ) |>group_by(pair_label) |>slice_head(n=1) %>%plot_dotsAll() +plot_annotation(title=glue::glue("Lowest rated pairs ( out of sets with n>={min_resp} ratings)"), theme =theme(plot.title =element_text(hjust =0.4)))d %>%filter(pair_label %in% {pairCounts |>filter(n>=min_resp) |>slice_max(mean_resp,n=n_show, with_ties=FALSE) |>pull(pair_label)} ) |>group_by(pair_label) |>slice_head(n=1) %>%plot_dotsAll() +plot_annotation(title=glue::glue("Highest rated pairs ( out of sets with n>={min_resp} ratings)"), theme =theme(plot.title =element_text(hjust =0.4)))```## Pattern Pair Table**All pairs with >=25 ratings**- click on column headers to change sort order - e.g. clicking on "Mean Rating" will toggle showing the pairs rated most similar or most dissimilar - clicking on "SD" will toggle showing the pairs with the most or least agreement in ratings- **note your screen may need to be at full width to see all columns**::: column-page-right```{r}#| cache: true# could try formatting table environment with #| column: pageplot_hist_pair <-function(Pair) { d |>filter(pair_label==Pair) |>ggplot(aes(x = response)) +geom_histogram(binwidth=1,fill ='dodgerblue4') +scale_x_continuous(breaks=seq(1, 9, by =1)) +coord_cartesian(xlim =c(1, 9)) +theme_minimal() +theme(axis.title.x=element_blank(),axis.title.y=element_blank(),axis.text.x=element_text(size=26)) }pat_table_plot <-function(Pair){ df <- d |>filter(pair_label==Pair) |>slice_head(n=1) pat1 <- df %>%mutate(pattern_1 = purrr::map(pattern_1, jsonlite::fromJSON)) %>%unnest(pattern_1) %>%mutate(y=-y, pat=item_label_1) |>select(pair_label,x,y,pat) pat2 <- df %>%mutate(pattern_2 = purrr::map(pattern_2, jsonlite::fromJSON)) %>%unnest(pattern_2) %>%mutate(y=-y, pat=item_label_2) |>select(pair_label,x,y,pat) pat <-rbind(pat1,pat2) pat |>ggplot(aes(x = x, y = y,fill=pat,col=pat)) +geom_point(alpha=2) +coord_cartesian(xlim =c(-25, 35.5), ylim =c(-25, 25)) +theme_minimal() +facet_wrap2(~pat,ncol=2,axes="all") +#theme_blank +theme_void() +theme(strip.text =element_text(size =7,hjust=.5),panel.spacing.x=unit(-7.3, "lines"), #strip.background = element_rect(colour = "black", linewidth = 2),legend.position ="none",axis.line.y =element_line(colour ="black", linewidth = .1)) }p5 <- pairCounts |>filter(n>=34) p5 |>arrange(mean_resp) |>relocate(pair_label,.after=sd) |>rename("Pair"=pair_label, "N"=n, "Mean Rating"=mean_resp, "SD"=sd) |>mutate(Rating_Dist=Pair) |>#group_by(Pair) |> gt() |>tab_options(table.font.size =px(8L)) |>cols_width( set ~px(116), Pair ~px(415),`N`~px(50),`Mean Rating`~px(90), SD ~px(55) ) |>fmt_number(decimals =1) |>#fmt_integer() |>cols_align('left', columns = set) |>text_transform(locations =cells_body(columns = Pair),fn =function(column) {map(column, pat_table_plot) |>ggplot_image(height =px(230), aspect_ratio =1.8) } ) |>text_transform(locations =cells_body(columns = Rating_Dist),fn =function(column) {map(column, plot_hist_pair) |>ggplot_image(height =px(150), aspect_ratio =1) } ) |>opt_interactive(page_size_default=5, use_page_size_select=TRUE, use_search=TRUE, use_resizers=TRUE,use_filters=TRUE, page_size_values =c(5, 10, 25, 50, 100)) ```:::<!-- ### Plot Pairs -->```{r}# #| fig-cap: dot plots# #| fig-width: 10# #| fig-height: 12# d %>% filter(trial==1) %>%# plot_dots()# d %>% filter(trial==1) %>%# plot_dots2()# d %>% filter(trial<2) %>%# plot_dotsAll()```<!-- ### Compare to original prototypes -->```{r}#| fig-width: 6#| fig-height: 9# d %>% filter(file %in% unique(d$file[1])) %>%# plot_dotsAll()# plot_dotsAll_orig <- function(df) {# plots <- list()# for (i in 1:nrow(df)) {# p1 <- df[i, ] %>%# pivot_longer(cols = starts_with("x"), names_to = "dot", values_to = "x") %>%# mutate(dot = as.numeric(str_remove(dot, "x"))) %>%# pivot_longer(cols = starts_with("y"), names_to = "dot2", values_to = "y") %>%# mutate(dot2 = as.numeric(str_remove(dot2, "y"))) %>%# filter(dot == dot2) %>%# ggplot(aes(x = x, y = y)) +# geom_point() +# coord_cartesian(xlim = c(-25, 25), ylim = c(-25, 25)) +# theme_minimal() +# labs(title = df$id[i]) + theme_blank# plots <- append(plots, list(p1))# }# patchwork::wrap_plots(plots, ncol = 1)# }# mc24_proto |> filter(file %in% unique(d$file[1])) %>% plot_dotsAll_orig()```## Stucture of dataframe after merging similarity ratings with CatLearn accuracy- Each subject in the 2024 study has a similarity score for each of their 3 categories. (averaged over 2 comparisons with that categories prototype)- The same category similarity scores are then compared to their accuracy for each of the 5 Pattern Tyeps (old, prototype, new low, new med, new high)- 5 Pattern types * 3 Categories = 15 comparisons per subject::: {#tbl-ee-brms1}| sbjCode | condit | Category | Pattern.Type | n | CatLearn Accuracy | n_rating | Category Similarity | sd | item ||:-------:|:------:|:--------:|:------------:|:-:|:-----------------:|:--------:|:-------------------:|:---:|:--------------:|| 316 | high | 1 | prototype | 1 | 1 | 60 | 5.1 | 2.6 | 316_high_1_285 || 316 | high | 1 | old | 9 | 0.4 | 60 | 5.1 | 2.6 | 316_high_1_285 || 316 | high | 1 | new_low | 3 | 0.3 | 60 | 5.1 | 2.6 | 316_high_1_285 || 316 | high | 1 | new_med | 6 | 0.3 | 60 | 5.1 | 2.6 | 316_high_1_285 || 316 | high | 1 | new_high | 9 | 0.4 | 60 | 5.1 | 2.6 | 316_high_1_285 || 316 | high | 2 | prototype | 1 | 0 | 60 | 3.8 | 2 | 316_high_2_327 || 316 | high | 2 | old | 9 | 0.7 | 60 | 3.8 | 2 | 316_high_2_327 || 316 | high | 2 | new_low | 3 | 0.7 | 60 | 3.8 | 2 | 316_high_2_327 || 316 | high | 2 | new_med | 6 | 0.2 | 60 | 3.8 | 2 | 316_high_2_327 || 316 | high | 2 | new_high | 9 | 0.2 | 60 | 3.8 | 2 | 316_high_2_327 || 316 | high | 3 | prototype | 1 | 0 | 60 | 5.2 | 2.4 | 316_high_3_287 || 316 | high | 3 | old | 9 | 0.1 | 60 | 5.2 | 2.4 | 316_high_3_287 || 316 | high | 3 | new_low | 3 | 0.7 | 60 | 5.2 | 2.4 | 316_high_3_287 || 316 | high | 3 | new_med | 6 | 0 | 60 | 5.2 | 2.4 | 316_high_3_287 || 316 | high | 3 | new_high | 9 | 0.3 | 60 | 5.2 | 2.4 | 316_high_3_287 |Example of how data is structure after combining similarity ratings with CatLearn accuracy. 5 Pattern types * 3 Categories = 15 rows per subject in the 2024 study{.striped .hover .sm}::: ```{r}#| label: tbl-htw-modelError-e1#| tbl-cap: "Example of how data is structure after combining similarity ratings with CatLearn accuracy. 5 Pattern types * 3 Categories = 15 rows per subject in the 2024 study"#| eval: truecat_sim_test %>%# round all numerics except sbjCode to 2 decimal placesmutate(across(where(is.numeric), ~round(., 1))) |>select(-id,-sim_group,-item_label) |>relocate(item,file, .after=sd) |>select(-Phase,-Block) |>rename("Category Similarity"= resp, "CatLearn Accuracy"= Corr) |> DT::datatable(options =list(pageLength =6))# cat_sim_test %>% # round all numerics except sbjCode to 2 decimal places# mutate(across(where(is.numeric), ~round(., 1))) |> select(-id,-sim_group,-item_label) |> # filter(sbjCode==316) |> # relocate(item,file, .after=sd) |># select(-Phase,-Block, -file) |> # rename("Category Similarity" = resp, "CatLearn Accuracy" = Corr) |> pander::pandoc.table(style="rmarkdown",split.table=Inf)```