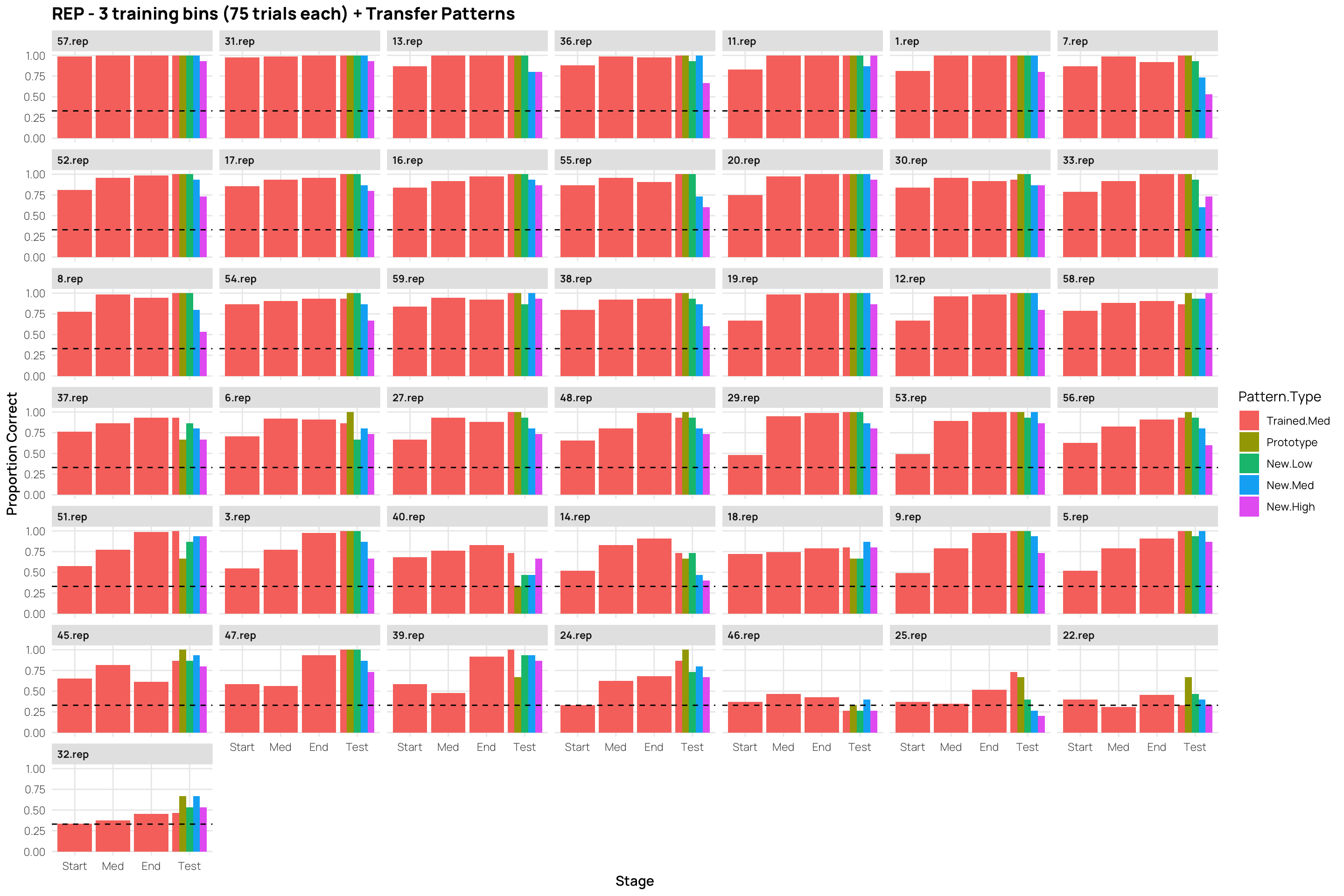
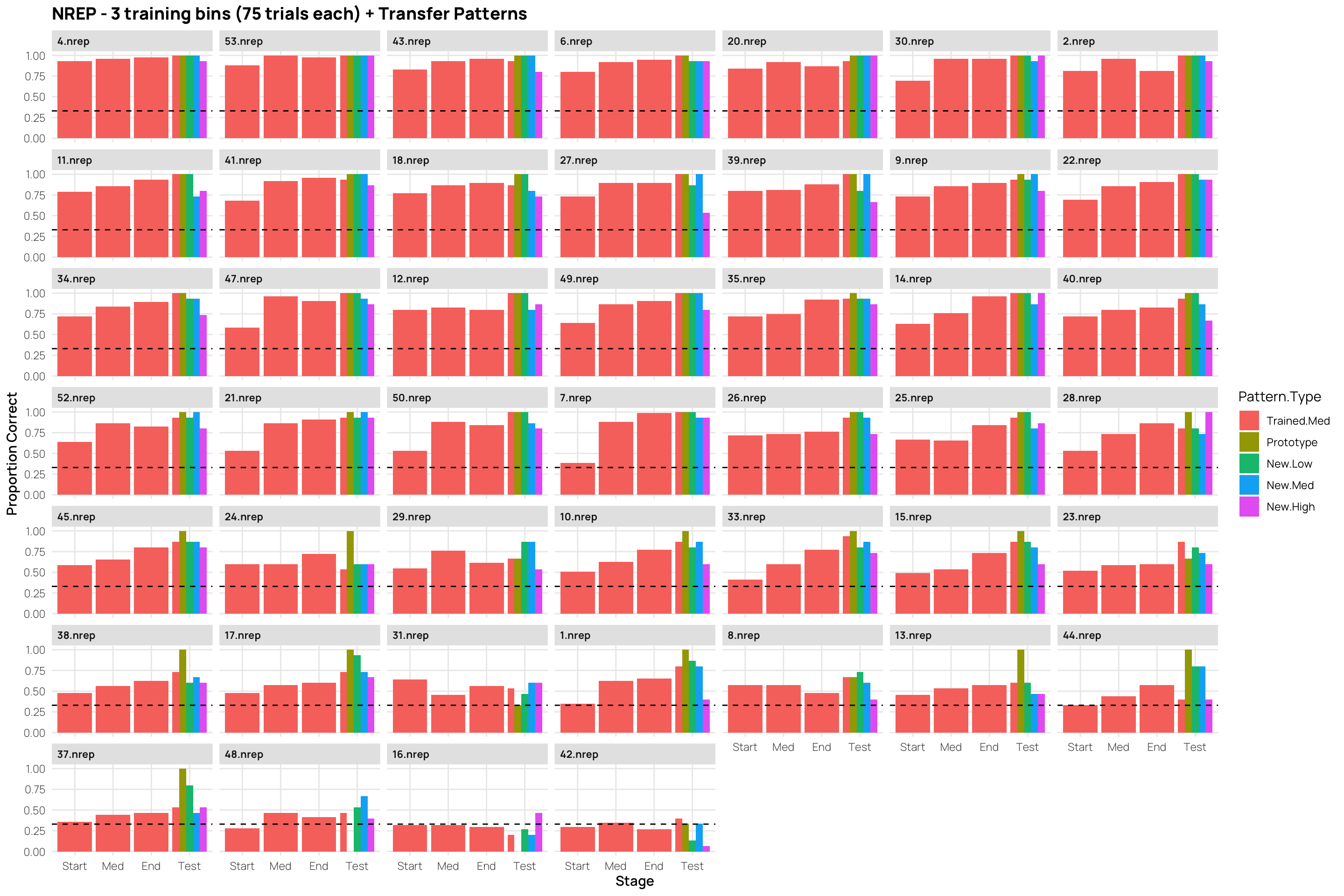
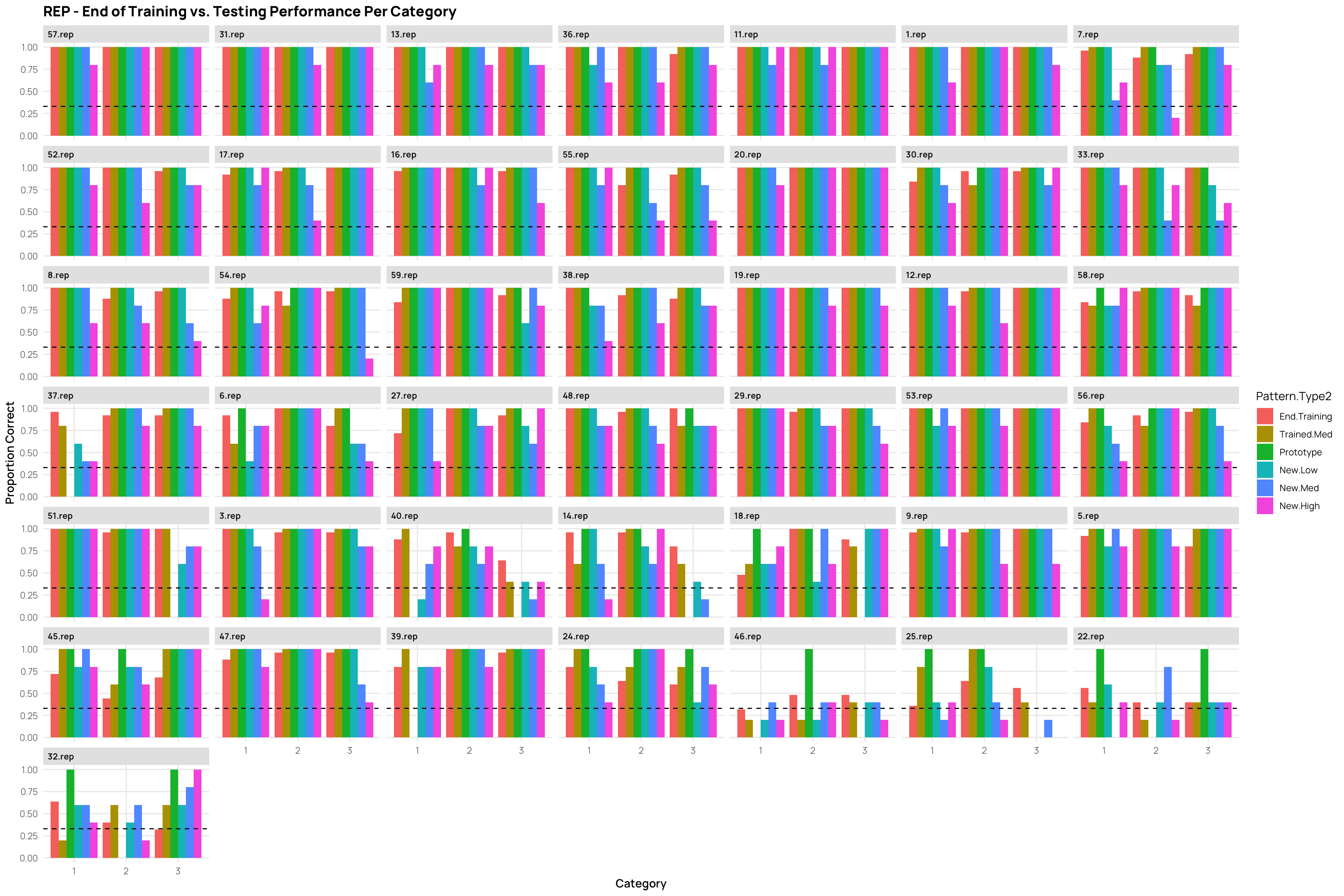
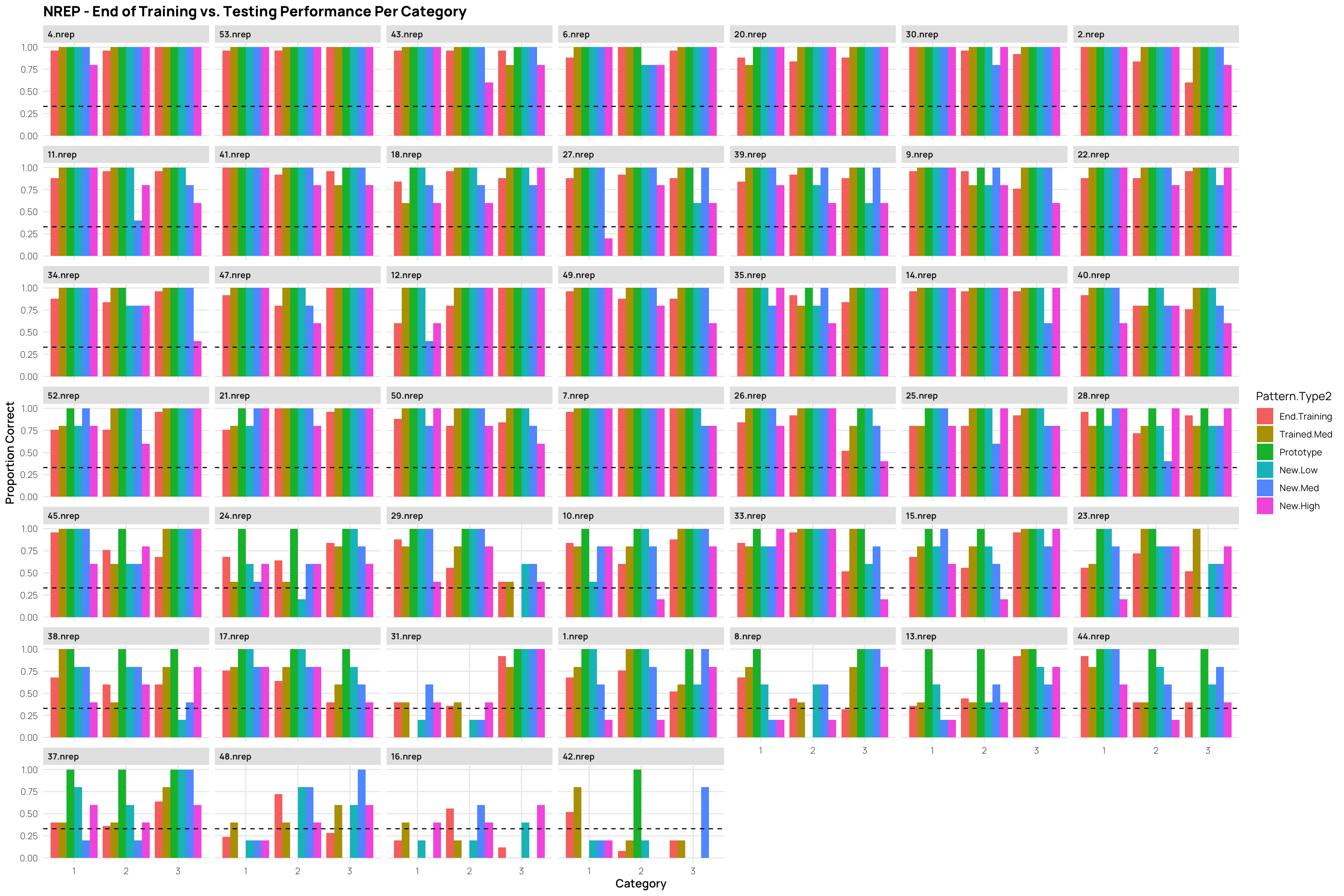
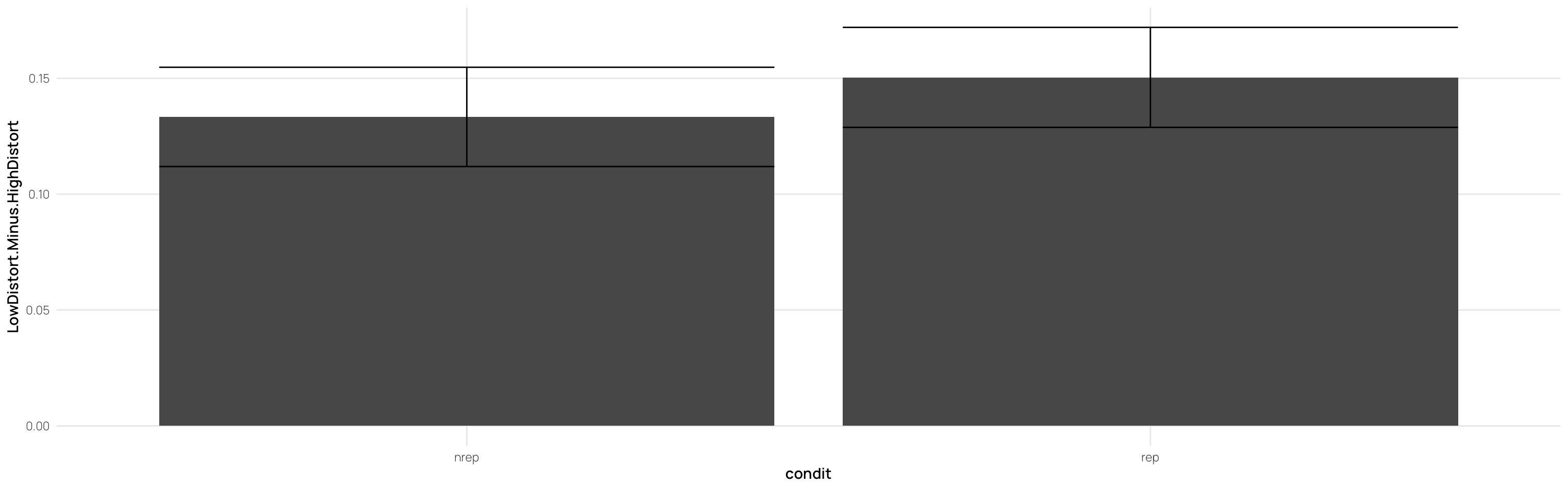
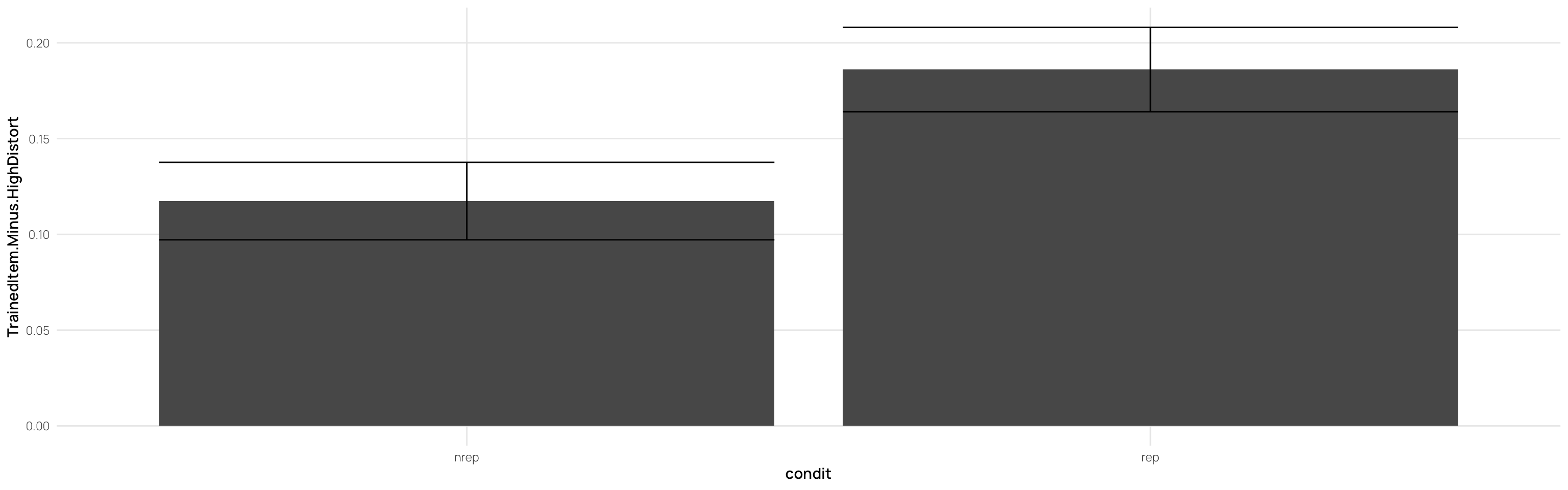
the learning phase consisted of 15 blocks, each of which had 15 trials (225 trials total).
Experiment 2
Testing - Splitting Peformance by End of Training
Display code
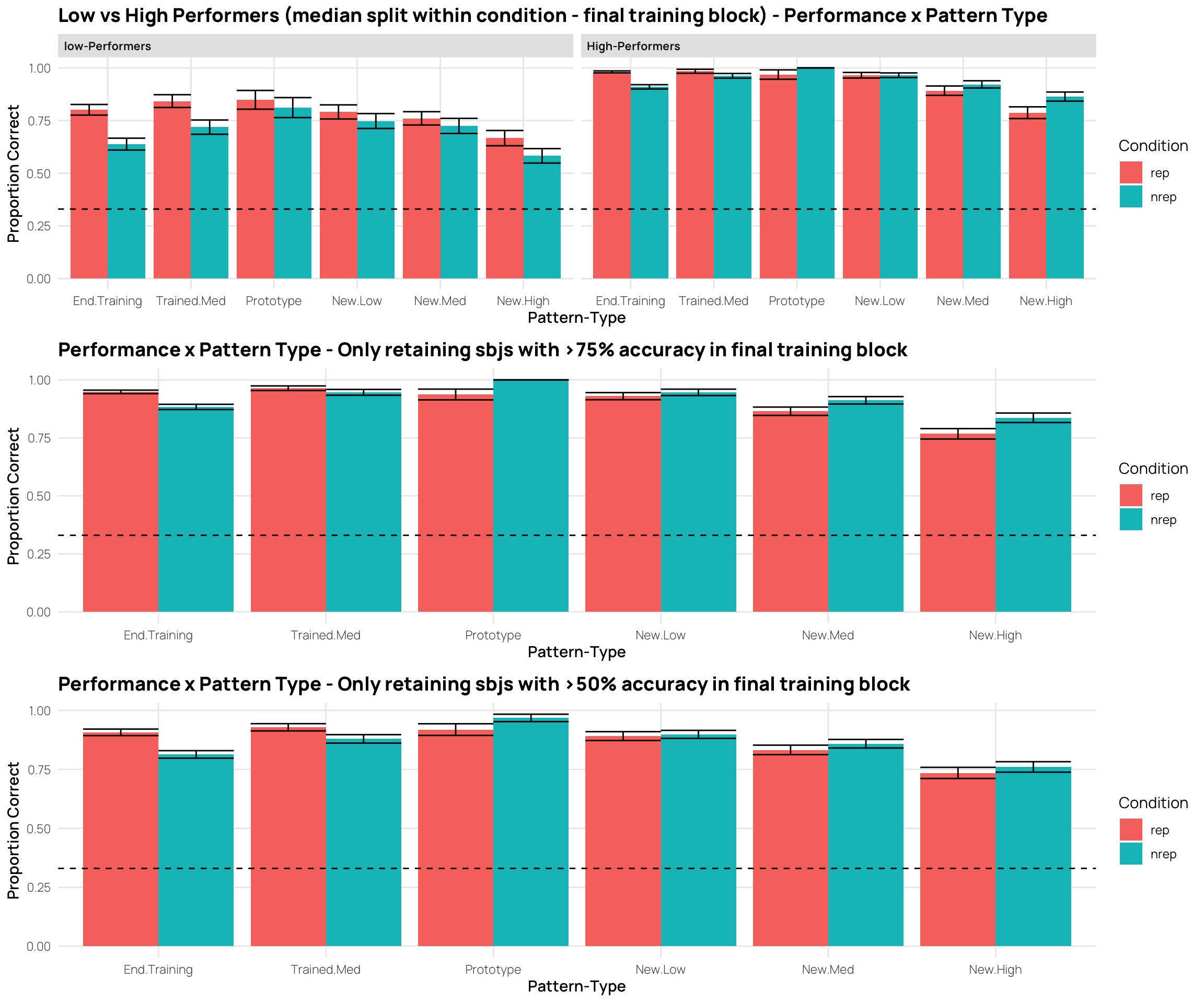
##| column: page-inset-rightlibrary(gghalves)ps<-dcp%>%ggplot(aes(x=Pattern.Type2,y=propCor,fill=Condition))+stat_summary(geom="bar",fun=mean,position=position_dodge())+stat_summary(geom="errorbar",fun.data=mean_se,position=position_dodge())+facet_wrap(~cq)+geom_hline(yintercept =.33,linetype="dashed")+xlab("Pattern-Type")+ylab("Proportion Correct")+ggtitle("Low vs High Performers (median split within condition - final training block) - Performance x Pattern Type")hd<-dcp%>%filter(Pattern.Type2=="New-High")%>%ggplot(aes(x=Pattern.Type2,y=propCor,fill=Condition))+geom_boxplot(outlier.shape=NA)+geom_jitter(alpha=.5)+facet_wrap(~cq)+xlab("Pattern-Type")+ggtitle("Low vs High Performers (median split within condition) - High Distortion Performance")+ylab("Proportion Correct")# dcp %>% filter(Pattern.Type2=="New-High") %>% ggplot(aes(x=Pattern.Type2,y=propCor,fill=Condition))+# geom_half_violin()+# geom_jitter(alpha=.5)+# facet_wrap(~cq)+ggtitle("Low vs High Performers (median split within condition) - High Distortion Performance")#ps#gridExtra::grid.arrange(ps,hd)p7<-dcp%>%filter(endTrain>.75)%>%ggplot(aes(x=Pattern.Type2,y=propCor,fill=Condition))+stat_summary(geom="bar",fun=mean,position=position_dodge())+stat_summary(geom="errorbar",fun.data=mean_se,position=position_dodge())+geom_hline(yintercept =.33,linetype="dashed")+xlab("Pattern-Type")+ylab("Proportion Correct")+ggtitle("Performance x Pattern Type - Only retaining sbjs with >75% accuracy in final training block")p5<-dcp%>%filter(endTrain>.50)%>%ggplot(aes(x=Pattern.Type2,y=propCor,fill=Condition))+stat_summary(geom="bar",fun=mean,position=position_dodge())+stat_summary(geom="errorbar",fun.data=mean_se,position=position_dodge())+geom_hline(yintercept =.33,linetype="dashed")+xlab("Pattern-Type")+ylab("Proportion Correct")+ggtitle("Performance x Pattern Type - Only retaining sbjs with >50% accuracy in final training block")gridExtra::grid.arrange(ps,p7,p5)
ANOVA Table (type III tests)
Effect DFn DFd F p p<.05 ges
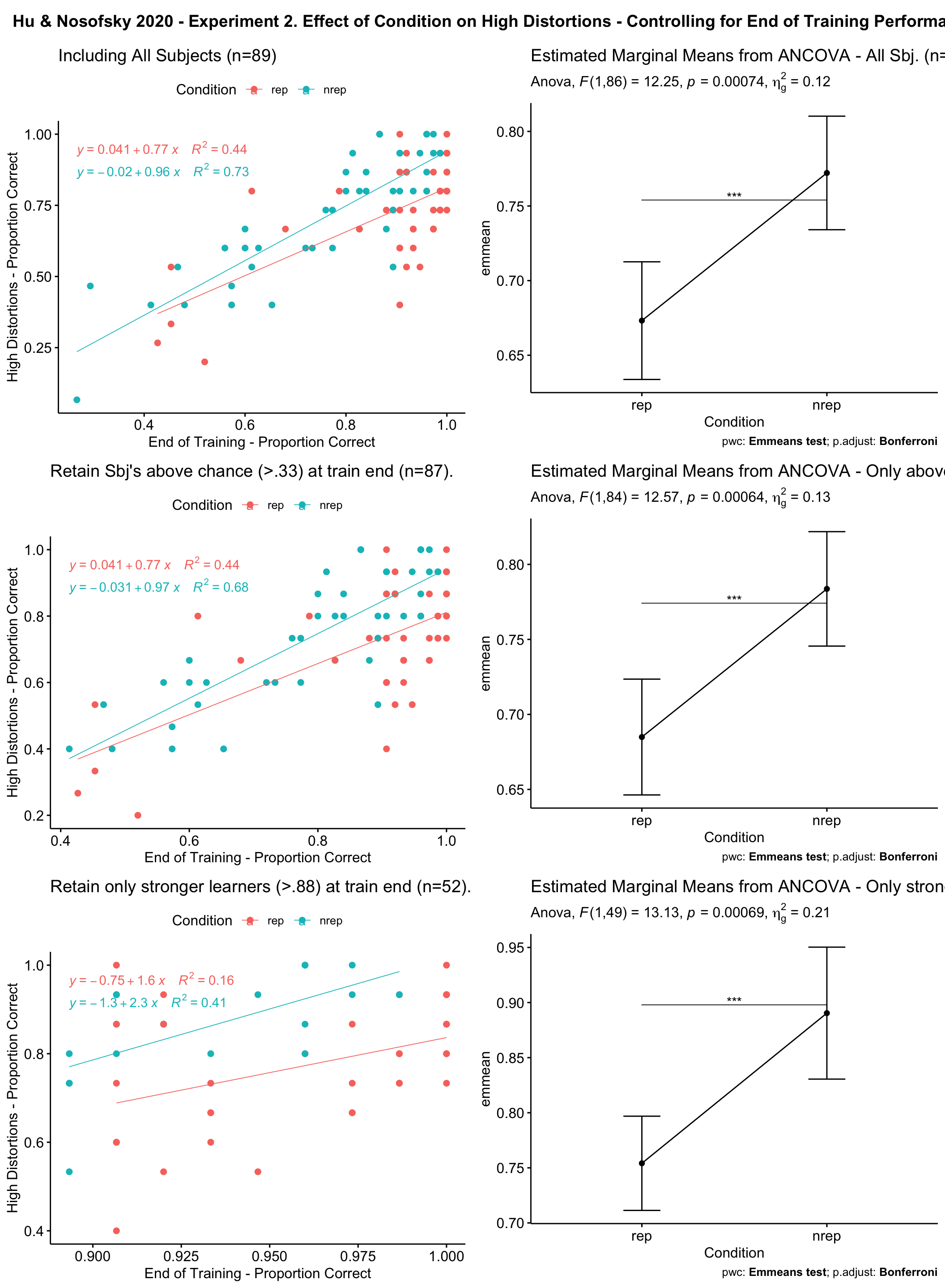
1 End.Training 1 49 13.847 0.000511 * 0.220
2 Condition 1 49 13.131 0.000689 * 0.211
Display code
#dc2 %>% anova_test(New.High ~condit*End.Training) # no sig. interactionpwc1<-dc2%>%emmeans_test(New.High~Condition,covariate=End.Training,p.adjust.method="bonferroni")%>%add_xy_position(x ="condit", fun ="mean_se")get_emmeans(pwc1)
pwc2<-dc2%>%filter(End.Training>.33)%>%emmeans_test(New.High~Condition,covariate=End.Training,p.adjust.method="bonferroni")%>%add_xy_position(x ="condit", fun ="mean_se")pwc3<-dc2%>%filter(End.Training>.88)%>%emmeans_test(New.High~Condition,covariate=End.Training,p.adjust.method="bonferroni")%>%add_xy_position(x ="condit", fun ="mean_se")ep1<-ggline(get_emmeans(pwc1), x ="Condition", y ="emmean")+geom_errorbar(aes(ymin =conf.low, ymax =conf.high), width =0.2)+stat_pvalue_manual(pwc1, hide.ns =TRUE, tip.length =FALSE)+labs(subtitle =get_test_label(at1, detailed =TRUE),caption =get_pwc_label(pwc1),title="Estimated Marginal Means from ANCOVA - All Sbj. (n=89)")ep2<-ggline(get_emmeans(pwc2), x ="Condition", y ="emmean")+geom_errorbar(aes(ymin =conf.low, ymax =conf.high), width =0.2)+stat_pvalue_manual(pwc2, hide.ns =TRUE, tip.length =FALSE)+labs(subtitle =get_test_label(at2, detailed =TRUE),caption =get_pwc_label(pwc2), title="Estimated Marginal Means from ANCOVA - Only above chance sbj (>.33,n=87)")ep3<-ggline(get_emmeans(pwc3), x ="Condition", y ="emmean")+geom_errorbar(aes(ymin =conf.low, ymax =conf.high), width =0.2)+stat_pvalue_manual(pwc3, hide.ns =TRUE, tip.length =FALSE)+labs(subtitle =get_test_label(at3, detailed =TRUE),caption =get_pwc_label(pwc3), title="Estimated Marginal Means from ANCOVA - Only strong learners (>.88; n=52)")gg.ac1<-ggscatter(dc2,x="End.Training",y="New.High",color="Condition",add="reg.line",add.params =list(size=.3))+stat_regline_equation(aes(label=paste(..eq.label.., ..rr.label..,sep="~~~~"),color=Condition))+ggtitle("Including All Subjects (n=89)")+ylab("High Distortions - Proportion Correct")+xlab("End of Training - Proportion Correct")gg.ac2<-dc2%>%filter(End.Training>.33)%>%ggscatter(.,x="End.Training",y="New.High",color="Condition",add="reg.line",add.params =list(size=.3))+stat_regline_equation(aes(label=paste(..eq.label.., ..rr.label..,sep="~~~~"),color=Condition))+ggtitle("Retain Sbj's above chance (>.33) at train end (n=87). ")+ylab("High Distortions - Proportion Correct")+xlab("End of Training - Proportion Correct")gg.ac3<-dc2%>%filter(End.Training>.88)%>%ggscatter(.,x="End.Training",y="New.High",color="Condition",add="reg.line",add.params =list(size=.3))+stat_regline_equation(aes(label=paste(..eq.label.., ..rr.label..,sep="~~~~"),color=Condition))+ggtitle("Retain only stronger learners (>.88) at train end (n=52). ")+ylab("High Distortions - Proportion Correct")+xlab("End of Training - Proportion Correct")gtitle=" Hu & Nosofsky 2020 - Experiment 2. Effect of Condition on High Distortions - Controlling for End of Training Performance"title=ggdraw()+draw_label(gtitle,fontface ='bold',x=0,hjust=0)+theme(plot.margin =margin(0, 0, 0, 7))plot_grid(title,NULL,gg.ac1,ep1,gg.ac2,ep2,gg.ac3,ep3,ncol=2,rel_heights=c(.1,1,1,1))
Individual Learning Curves
Display code
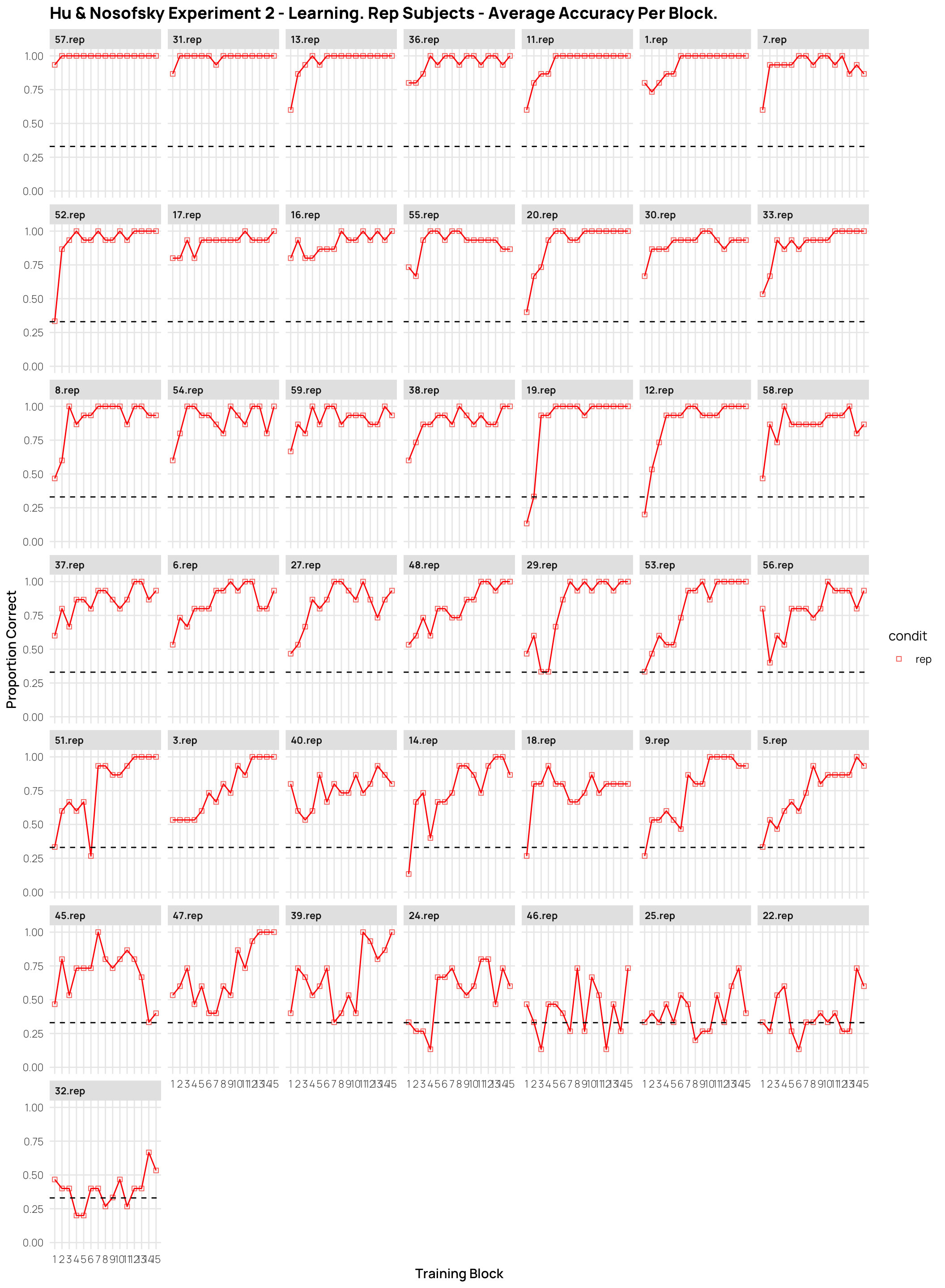
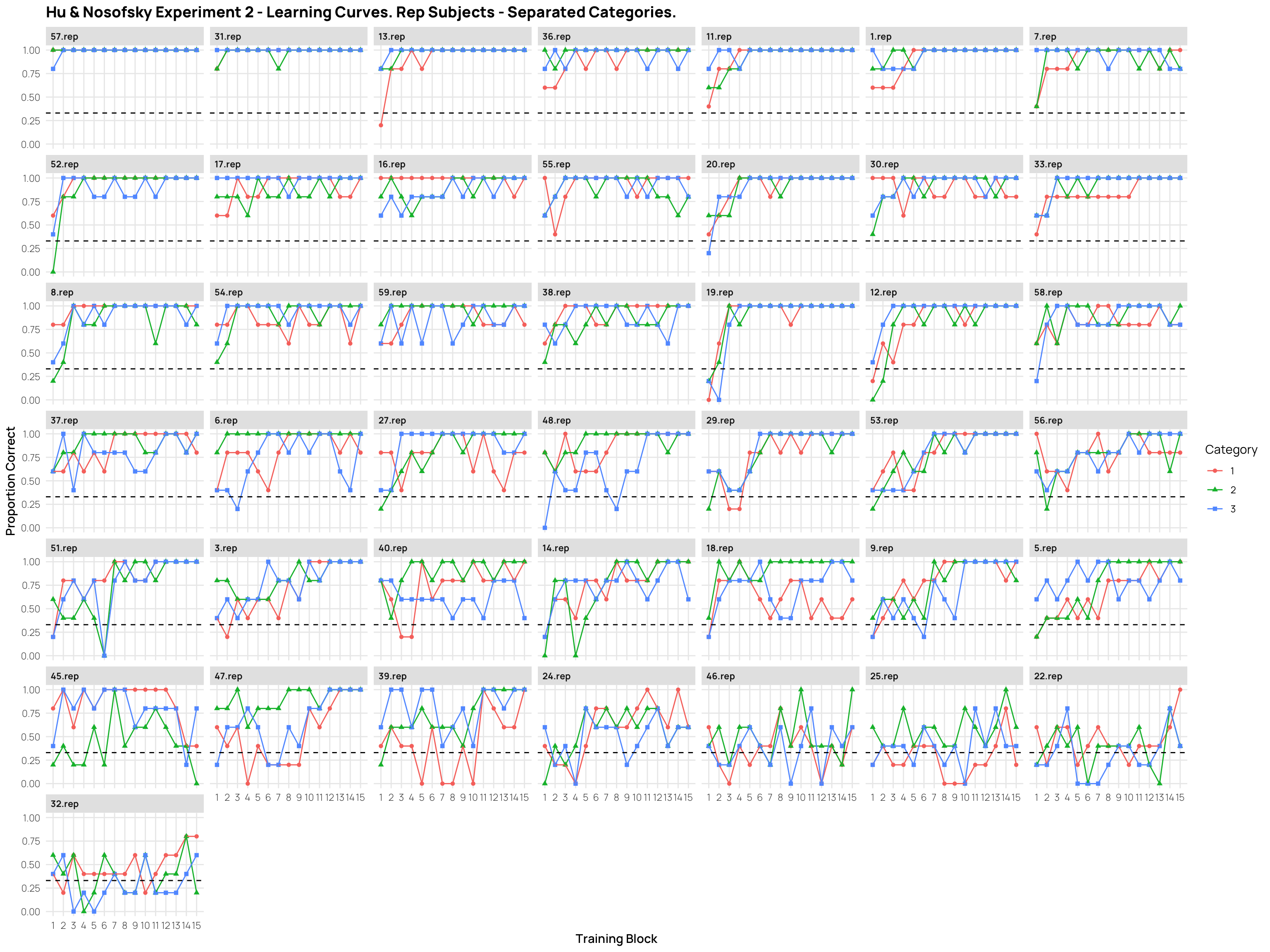
###| column: screen-inset-rightdCatTrainAvg%>%filter(condit=="rep")%>%ggplot(aes(x=Block,y=propCor,col=condit))+stat_summary(shape=0,geom="point",fun="mean")+stat_summary(geom="line",fun="mean",col="red")+facet_wrap(~id)+ylim(c(0,1))+geom_hline(yintercept =.33,linetype="dashed")+ggtitle("Hu & Nosofsky Experiment 2 - Learning. Rep Subjects - Average Accuracy Per Block.")+xlab("Training Block")+ylab("Proportion Correct")+scale_x_continuous(breaks=seq(1,15))
Display code
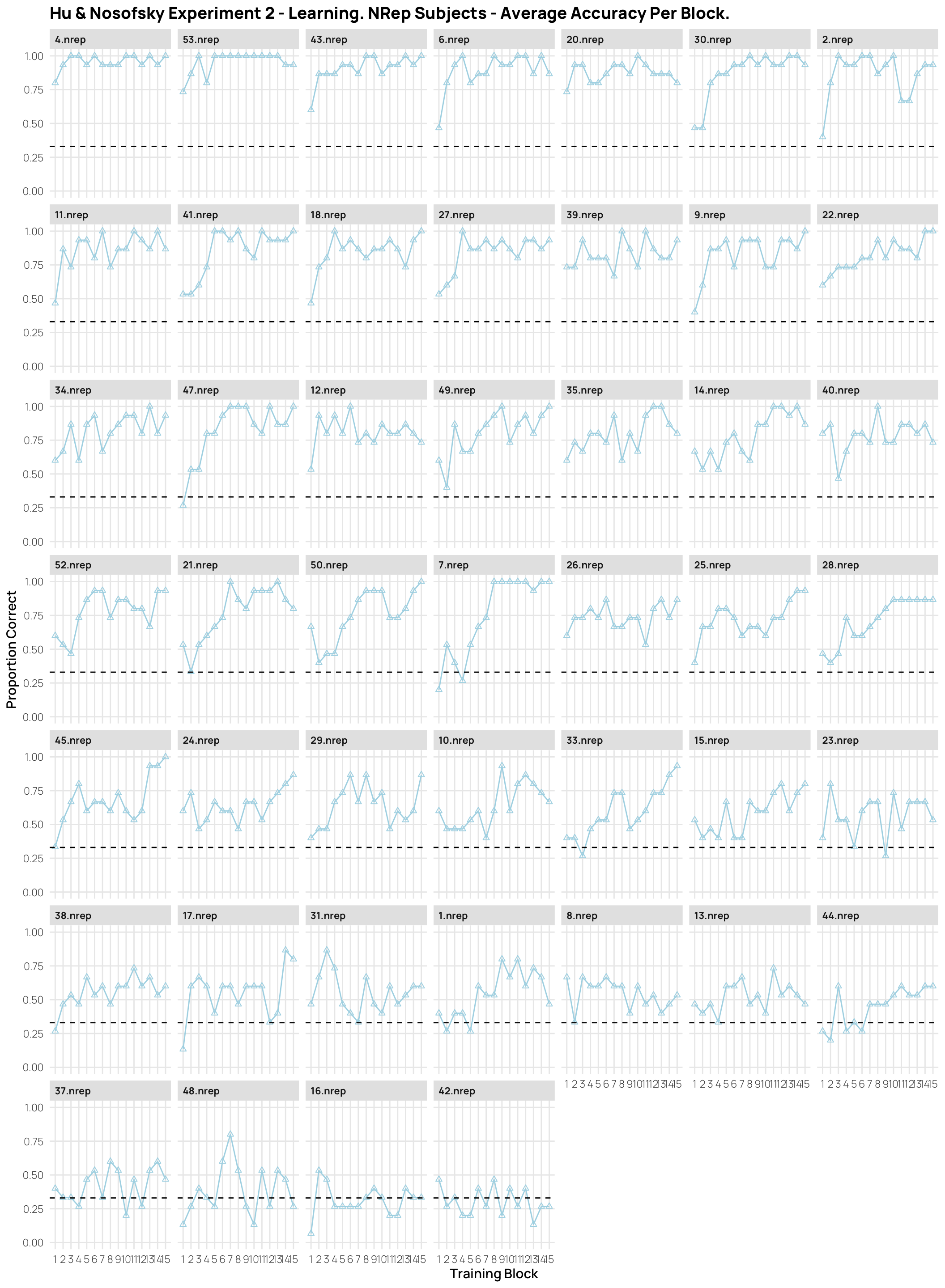
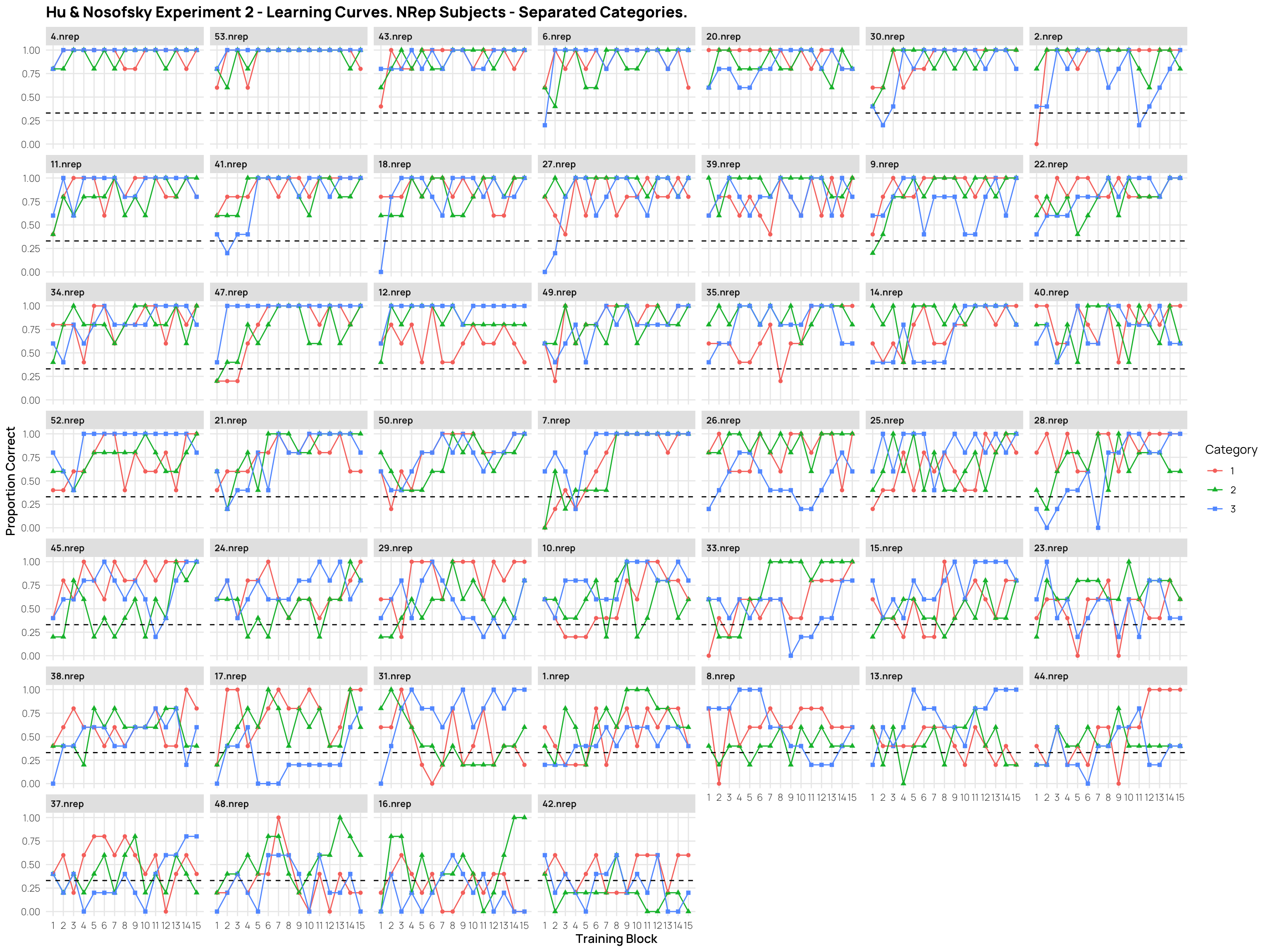
dCatTrainAvg%>%filter(condit=="nrep")%>%ggplot(aes(x=Block,y=propCor,col=condit))+stat_summary(shape=2, geom="point",fun="mean",col="lightblue")+stat_summary(geom="line",fun="mean",col="lightblue")+facet_wrap(~id)+ylim(c(0,1))+geom_hline(yintercept =.33,linetype="dashed")+facet_wrap(~id)+ggtitle("Hu & Nosofsky Experiment 2 - Learning. NRep Subjects - Average Accuracy Per Block.")+xlab("Training Block")+ylab("Proportion Correct")+scale_x_continuous(breaks=seq(1,15))
Experiment 2 - separate category - learning curves
Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1), 1–48. https://doi.org/10.18637/jss.v067.i01
Wickham, H., Averick, M., Bryan, J., Chang, W., McGowan, L. D., François, R., Grolemund, G., Hayes, A., Henry, L., Hester, J., Kuhn, M., Pedersen, T. L., Miller, E., Bache, S. M., Müller, K., Ooms, J., Robinson, D., Seidel, D. P., Spinu, V., … Yutani, H. (2019). Welcome to the tidyverse. Journal of Open Source Software, 4(43), 1686. https://doi.org/10.21105/joss.01686
Xie, Y. (2014). knitr: A comprehensive tool for reproducible research in R. In V. Stodden, F. Leisch, & R. D. Peng (Eds.), Implementing reproducible computational research. Chapman; Hall/CRC.
Xie, Y. (2015). Dynamic documents with R and knitr (2nd ed.). Chapman; Hall/CRC. https://yihui.org/knitr/
Xie, Y. (2024). knitr: A general-purpose package for dynamic report generation in r. https://yihui.org/knitr/
Source Code
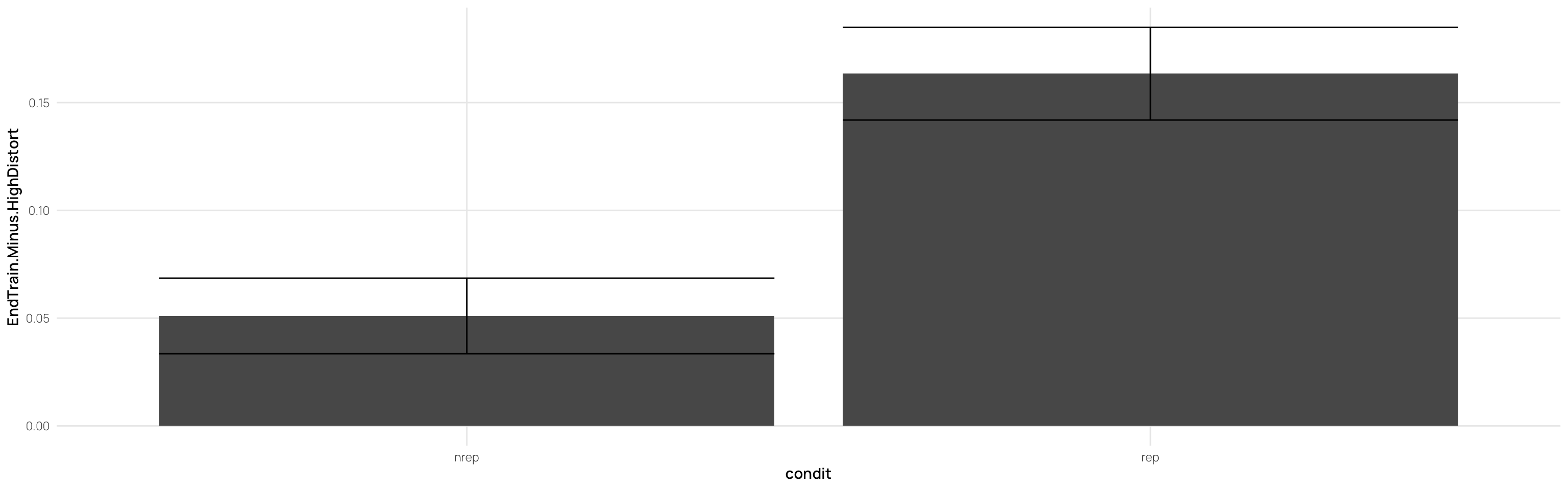
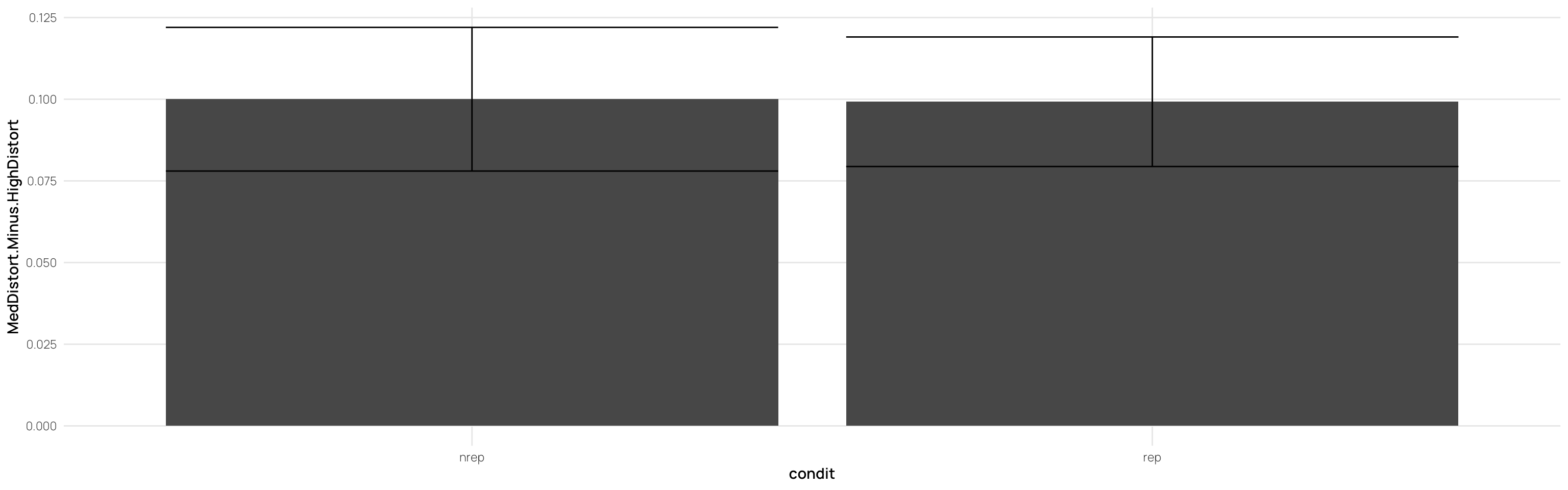
---title: Hu & Nosofsky 2022date: last-modifiedlightbox: truealiases: - /dp_22.html# resource-path: ["./assets/"]#bibliography: /assets/grateful-refs.bibformat: html: grid: sidebar-width: 230px body-width: 1200px margin-width: 150px gutter-width: 1.0remfig-width: 16toc: truetoc-depth: 4code-fold: truecode-tools: truecode-summary: "Display code"execute: warning: false eval: true---{{< include /assets/setup.qmd >}}## Hu & Nosofsky 2022 (exp 2)### Subjects- 89 undergraduates from Indiana University.- Participation as partial fulfillment of an introductory psychology course requirement.- Random assignment to conditions: 43 in REP, 46 in NREP.- Normal or corrected-to-normal vision.### Procedure#### Learning Phase- **Task**: Classify dot patterns into three categories: A, B, and C.- **Trial Structure**: - Pattern presented on screen. - Subject classifies pattern by pressing a corresponding button. - Immediate feedback provided.- **Conditions**: - **Repeating Condition (REP)**: - 15 unique learning patterns (5 per category). - Patterns repeated across 15 blocks (225 trials total). - **Nonrepeating Condition (NREP)**: - 75 unique learning patterns (5 per category per block). - No repetitions (225 trials total).#### Transfer Phase- **Task**: Continue classifying patterns into the same three categories.- **Transfer Patterns**: - 15 old distortions (5 per category). - 3 prototypes (one per category). - 15 low-level distortions (5 per category). - 15 new medium-level distortions (5 per category). - 15 high-level distortions (5 per category).- **Trial Structure**: - Each pattern presented once (63 trials total). - Random order of presentation for each subject.```{r load}pacman::p_load(dplyr,purrr,tidyr,ggplot2, here, patchwork, conflicted, viridis, gghalves,grateful)conflict_prefer_all("dplyr", quiet = TRUE)source(here::here("R/read_22.R"))source(here::here("R/fun_plot.R"))#lmc22 <- readRDS(here("data","lmc22.rds"))#theme_set(theme_bw())dcp <- merge(dCatAvg2,sbjTrainAvg,by=c("id","condit","Condition"))dc <- dCatAvg2 %>% select(id,condit,Condition,Pattern.Type2,Category,propCor) %>% pivot_wider(names_from = "Pattern.Type2",values_from = "propCor") %>% mutate(EndTrain.Minus.HighDistort= End.Training-New.High, MedDistort.Minus.HighDistort=New.Med-New.High, LowDistort.Minus.HighDistort=New.Low-New.High, TrainedItem.Minus.HighDistort=Trained.Med-New.High, Prototype.Minus.HighDistort=Prototype-New.High) dc <- merge(dc,sbjTrainAvg,by=c("id","condit","Condition"))dc2 <- dc %>% group_by(id,condit,Condition,cq) %>% summarise(End.Training=mean(End.Training),New.High=mean(New.High)) %>% as.data.frame()```- the learning phase consisted of 15 blocks, each of which had 15 trials (225 trials total). # Experiment 2## Testing - Splitting Peformance by End of Training::: column-page-inset-right```{r}#| fig-width: 12#| fig-height: 10##| column: page-inset-rightlibrary(gghalves)ps <- dcp %>%ggplot(aes(x=Pattern.Type2,y=propCor,fill=Condition))+stat_summary(geom="bar",fun=mean,position=position_dodge())+stat_summary(geom="errorbar",fun.data=mean_se,position=position_dodge())+facet_wrap(~cq)+geom_hline(yintercept = .33,linetype="dashed")+xlab("Pattern-Type")+ylab("Proportion Correct")+ggtitle("Low vs High Performers (median split within condition - final training block) - Performance x Pattern Type")hd<- dcp %>%filter(Pattern.Type2=="New-High")%>%ggplot(aes(x=Pattern.Type2,y=propCor,fill=Condition))+geom_boxplot(outlier.shape=NA)+geom_jitter(alpha=.5)+facet_wrap(~cq)+xlab("Pattern-Type")+ggtitle("Low vs High Performers (median split within condition) - High Distortion Performance")+ylab("Proportion Correct")# dcp %>% filter(Pattern.Type2=="New-High") %>% ggplot(aes(x=Pattern.Type2,y=propCor,fill=Condition))+# geom_half_violin()+# geom_jitter(alpha=.5)+# facet_wrap(~cq)+ggtitle("Low vs High Performers (median split within condition) - High Distortion Performance")#ps#gridExtra::grid.arrange(ps,hd)p7<- dcp %>%filter(endTrain>.75) %>%ggplot(aes(x=Pattern.Type2,y=propCor,fill=Condition))+stat_summary(geom="bar",fun=mean,position=position_dodge())+stat_summary(geom="errorbar",fun.data=mean_se,position=position_dodge())+geom_hline(yintercept = .33,linetype="dashed")+xlab("Pattern-Type")+ylab("Proportion Correct")+ggtitle("Performance x Pattern Type - Only retaining sbjs with >75% accuracy in final training block")p5 <- dcp %>%filter(endTrain>.50) %>%ggplot(aes(x=Pattern.Type2,y=propCor,fill=Condition))+stat_summary(geom="bar",fun=mean,position=position_dodge())+stat_summary(geom="errorbar",fun.data=mean_se,position=position_dodge())+geom_hline(yintercept = .33,linetype="dashed")+xlab("Pattern-Type")+ylab("Proportion Correct")+ggtitle("Performance x Pattern Type - Only retaining sbjs with >50% accuracy in final training block")gridExtra::grid.arrange(ps,p7,p5)# dCatAvg2 %>% ggplot(aes(x=Pattern.Type2,y=propCor,fill=Condition))+# stat_summary(geom="bar",fun=mean,position=position_dodge())+# stat_summary(geom="errorbar",fun.data=mean_se,position=position_dodge())+facet_wrap(~cq)+# stat_summary(geom="point")# geom_hline(yintercept = .33,linetype="dashed")+# ggtitle("")+ylab("Proportion Correct")# dCatAvg2 %>% filter() %>% ggplot(aes(x=Pattern.Type2,y=propCor,fill=Pattern.Type2))+# stat_summary(geom="bar",fun=mean,position=position_dodge())+# stat_summary(geom="errorbar",fun.data=mean_se,position=position_dodge())+facet_wrap(~condit)+# geom_hline(yintercept = .33,linetype="dashed")+# ggtitle("")+ylab("Proportion Correct")# # # dCatAvg3 %>% filter() %>% ggplot(aes(x=Pattern.Type2,y=propCor,fill=Pattern.Type2))+# stat_summary(geom="bar",fun=mean,position=position_dodge())+# stat_summary(geom="errorbar",fun.data=mean_se,position=position_dodge())+facet_wrap(~condit)+# geom_hline(yintercept = .33,linetype="dashed")+# ggtitle("")+ylab("Proportion Correct")```:::## Controlling for End of Training Performace```{r fig.height=12,fig.width=16}#| fig-width: 11#| fig-height: 15#| column: page-inset-rightlibrary(rstatix)library(ggpubr)library(emmeans)library(cowplot)# dc2 %>% filter() %>% ggplot(aes(x=End.Training,y=New.High,color=condit))+geom_point()+geom_smooth(method="lm")# dc2 %>% filter(End.Training>.33, New.High>.33) %>% ggplot(aes(x=End.Training,y=New.High,color=condit))+geom_point()+geom_smooth(method="lm")(at1 <- dc2 %>% anova_test(dv=New.High,between=Condition,covariate = End.Training,wid=id,type=3))(at2 <- dc2 %>% filter(End.Training>.33) %>% anova_test(dv=New.High,between=Condition,covariate = End.Training,wid=id,type=3))(at3 <- dc2 %>% filter(End.Training>.88) %>% anova_test(dv=New.High,between=Condition,covariate = End.Training,wid=id,type=3))#dc2 %>% anova_test(New.High ~condit*End.Training) # no sig. interactionpwc1 <- dc2 %>% emmeans_test(New.High ~ Condition,covariate=End.Training,p.adjust.method="bonferroni")%>% add_xy_position(x = "condit", fun = "mean_se")get_emmeans(pwc1)pwc2 <- dc2 %>% filter(End.Training>.33) %>% emmeans_test(New.High ~ Condition,covariate=End.Training,p.adjust.method="bonferroni")%>% add_xy_position(x = "condit", fun = "mean_se")pwc3 <- dc2 %>% filter(End.Training>.88) %>% emmeans_test(New.High ~ Condition,covariate=End.Training,p.adjust.method="bonferroni")%>% add_xy_position(x = "condit", fun = "mean_se")ep1<-ggline(get_emmeans(pwc1), x = "Condition", y = "emmean") + geom_errorbar(aes(ymin = conf.low, ymax = conf.high), width = 0.2) + stat_pvalue_manual(pwc1, hide.ns = TRUE, tip.length = FALSE) + labs(subtitle = get_test_label(at1, detailed = TRUE),caption = get_pwc_label(pwc1),title="Estimated Marginal Means from ANCOVA - All Sbj. (n=89)" )ep2<-ggline(get_emmeans(pwc2), x = "Condition", y = "emmean") + geom_errorbar(aes(ymin = conf.low, ymax = conf.high), width = 0.2) + stat_pvalue_manual(pwc2, hide.ns = TRUE, tip.length = FALSE) + labs(subtitle = get_test_label(at2, detailed = TRUE),caption = get_pwc_label(pwc2), title= "Estimated Marginal Means from ANCOVA - Only above chance sbj (>.33,n=87)")ep3<-ggline(get_emmeans(pwc3), x = "Condition", y = "emmean") + geom_errorbar(aes(ymin = conf.low, ymax = conf.high), width = 0.2) + stat_pvalue_manual(pwc3, hide.ns = TRUE, tip.length = FALSE) + labs(subtitle = get_test_label(at3, detailed = TRUE),caption = get_pwc_label(pwc3), title= "Estimated Marginal Means from ANCOVA - Only strong learners (>.88; n=52)")gg.ac1 <- ggscatter(dc2,x="End.Training",y="New.High",color="Condition",add="reg.line",add.params = list(size=.3))+ stat_regline_equation(aes(label=paste(..eq.label.., ..rr.label..,sep="~~~~"),color=Condition))+ ggtitle("Including All Subjects (n=89)")+ylab("High Distortions - Proportion Correct")+xlab("End of Training - Proportion Correct")gg.ac2 <- dc2 %>% filter(End.Training>.33) %>% ggscatter(.,x="End.Training",y="New.High",color="Condition",add="reg.line",add.params = list(size=.3))+ stat_regline_equation(aes(label=paste(..eq.label.., ..rr.label..,sep="~~~~"),color=Condition))+ ggtitle("Retain Sbj's above chance (>.33) at train end (n=87). ")+ylab("High Distortions - Proportion Correct")+xlab("End of Training - Proportion Correct")gg.ac3 <- dc2 %>% filter(End.Training>.88) %>% ggscatter(.,x="End.Training",y="New.High",color="Condition",add="reg.line",add.params = list(size=.3))+ stat_regline_equation(aes(label=paste(..eq.label.., ..rr.label..,sep="~~~~"),color=Condition))+ ggtitle("Retain only stronger learners (>.88) at train end (n=52). ")+ylab("High Distortions - Proportion Correct")+xlab("End of Training - Proportion Correct")gtitle=" Hu & Nosofsky 2020 - Experiment 2. Effect of Condition on High Distortions - Controlling for End of Training Performance"title = ggdraw()+draw_label(gtitle,fontface = 'bold',x=0,hjust=0)+theme(plot.margin = margin(0, 0, 0, 7))plot_grid(title,NULL,gg.ac1,ep1,gg.ac2,ep2,gg.ac3,ep3,ncol=2,rel_heights=c(.1,1,1,1))```## Individual Learning Curves::: column-screen-inset-right```{r fig.height=10,fig.width=16}#| fig-width: 11#| fig-height: 15###| column: screen-inset-rightdCatTrainAvg %>% filter(condit=="rep") %>% ggplot(aes(x=Block,y=propCor,col=condit))+ stat_summary(shape=0,geom="point",fun="mean")+ stat_summary(geom="line",fun="mean",col="red")+facet_wrap(~id)+ylim(c(0,1))+ geom_hline(yintercept = .33,linetype="dashed")+ ggtitle("Hu & Nosofsky Experiment 2 - Learning. Rep Subjects - Average Accuracy Per Block.")+ xlab("Training Block")+ylab("Proportion Correct")+scale_x_continuous(breaks=seq(1,15))dCatTrainAvg %>% filter(condit=="nrep") %>% ggplot(aes(x=Block,y=propCor,col=condit))+ stat_summary(shape=2, geom="point",fun="mean",col="lightblue")+ stat_summary(geom="line",fun="mean",col="lightblue")+facet_wrap(~id)+ylim(c(0,1))+ geom_hline(yintercept = .33,linetype="dashed")+ facet_wrap(~id)+ggtitle("Hu & Nosofsky Experiment 2 - Learning. NRep Subjects - Average Accuracy Per Block.")+ xlab("Training Block")+ylab("Proportion Correct")+scale_x_continuous(breaks=seq(1,15))```:::## Experiment 2 - separate category - learning curves::: column-screen-inset-right```{r fig.height=12,fig.width=16}##| column: screen-inset-rightdCatTrainAvg2 %>% filter(condit=="rep") %>% ggplot(aes(x=Block,y=propCor,col=Category,shape=Category))+ stat_summary(geom="point",fun="mean")+ stat_summary(geom="line",fun="mean")+facet_wrap(~id)+ylim(c(0,1))+ geom_hline(yintercept = .33,linetype="dashed")+ ggtitle("Hu & Nosofsky Experiment 2 - Learning Curves. Rep Subjects - Separated Categories.")+ xlab("Training Block")+ylab("Proportion Correct")+scale_x_continuous(breaks=seq(1,15))dCatTrainAvg2 %>% filter(condit=="nrep") %>% ggplot(aes(x=Block,y=propCor,col=Category,shape=Category))+ stat_summary(geom="point",fun="mean")+ stat_summary(geom="line",fun="mean")+facet_wrap(~id)+ylim(c(0,1))+ geom_hline(yintercept = .33,linetype="dashed")+ facet_wrap(~id)+ggtitle("Hu & Nosofsky Experiment 2 - Learning Curves. NRep Subjects - Separated Categories.")+ xlab("Training Block")+ylab("Proportion Correct")+scale_x_continuous(breaks=seq(1,15))```:::## Experiment 2 - 3 Training Stages + Transfer Patterns```{r fig.height=10,fig.width=15}#| column: screen-inset-rightdCatAvg %>% filter(condit=="rep") %>% ggplot(aes(x=Stage,y=propCor,fill=Pattern.Type))+ stat_summary(geom="bar",fun=mean,position=position_dodge())+ stat_summary(geom="errorbar",fun.data=mean_se,position=position_dodge())+facet_wrap(~id)+ geom_hline(yintercept = .33,linetype="dashed")+ ggtitle("REP - 3 training bins (75 trials each) + Transfer Patterns")+ylab("Proportion Correct")dCatAvg %>% filter(condit=="nrep") %>% ggplot(aes(x=Stage,y=propCor,fill=Pattern.Type))+ stat_summary(geom="bar",fun=mean,position=position_dodge())+ stat_summary(geom="errorbar",fun.data=mean_se,position=position_dodge())+facet_wrap(~id)+ geom_hline(yintercept = .33,linetype="dashed")+ ggtitle("NREP - 3 training bins (75 trials each) + Transfer Patterns")+ylab("Proportion Correct")# # dCatAvg %>% filter() %>% ggplot(aes(x=Stage,y=propCor,fill=Pattern.Type))+# stat_summary(geom="bar",fun=mean,position=position_dodge())+# stat_summary(geom="errorbar",fun.data=mean_se,position=position_dodge())+facet_wrap(~condit)+ggtitle("nrep")# # dCatAvg %>% filter() %>% ggplot(aes(x=Pattern.Type,y=propCor,fill=condit))+# stat_summary(geom="bar",fun=mean,position=position_dodge())+# stat_summary(geom="errorbar",fun.data=mean_se,position=position_dodge())+facet_wrap(~Stage)+ggtitle("")# # dCatAvg %>% filter() %>% ggplot(aes(x=Pattern.Type,y=propCor,col=condit))+# geom_boxplot(position=position_dodge())+facet_wrap(~Stage)```# Experiment 2 - Separate Categories x stage```{r fig.height=12,fig.width=18}dCatAvg2 %>% filter(condit=="rep") %>% ggplot(aes(x=Category,y=propCor,fill=Pattern.Type2))+ stat_summary(geom="bar",fun=mean,position=position_dodge())+ stat_summary(geom="errorbar",fun.data=mean_se,position=position_dodge())+facet_wrap(~id)+ geom_hline(yintercept = .33,linetype="dashed")+ ggtitle("REP - End of Training vs. Testing Performance Per Category")+ylab("Proportion Correct")dCatAvg2 %>% filter(condit=="nrep") %>% ggplot(aes(x=Category,y=propCor,fill=Pattern.Type2))+ stat_summary(geom="bar",fun=mean,position=position_dodge())+ stat_summary(geom="errorbar",fun.data=mean_se,position=position_dodge())+facet_wrap(~id)+ geom_hline(yintercept = .33,linetype="dashed")+ ggtitle("NREP - End of Training vs. Testing Performance Per Category")+ylab("Proportion Correct")``````{r}dc %>%ggplot(aes(x=condit,y=EndTrain.Minus.HighDistort))+stat_summary(geom="bar",fun=mean)+stat_summary(geom="errorbar",fun.data=mean_se)dc %>%ggplot(aes(x=condit,y=MedDistort.Minus.HighDistort))+stat_summary(geom="bar",fun=mean)+stat_summary(geom="errorbar",fun.data=mean_se)dc %>%ggplot(aes(x=condit,y=LowDistort.Minus.HighDistort))+stat_summary(geom="bar",fun=mean)+stat_summary(geom="errorbar",fun.data=mean_se)dc %>%ggplot(aes(x=condit,y=TrainedItem.Minus.HighDistort))+stat_summary(geom="bar",fun=mean)+stat_summary(geom="errorbar",fun.data=mean_se)# dc %>% filter(condit=="rep") %>% ungroup() %>% select(End.Training,`New-High`) %>% cor# dc %>% filter(condit=="nrep") %>% ungroup() %>% select(End.Training,`New-High`) %>% cor()``````{r fig.width=12,fig.height=9}#| eval: false#| include: false# other settings for stylenudge_vp= -1.3spacing_factor=3dCatAvg2$Bin <- as.numeric(dCatAvg2$Pattern.Type2)*spacing_factorrep1=subset(dCatAvg2, dCatAvg2$Condition=="rep")nrep1=subset(dCatAvg2, dCatAvg2$Condition=="nrep")set.seed(521)rep1$jbin_w <- jitter(rep1$Bin, amount=.27) -0.3nrep1$jbin_nw <- rep1$jbin_w[1:nrow(nrep1)] + 0.6pe3 <- ggplot(data=dCatAvg2, aes(x=Bin, y= propCor, color =Condition, group=Condition, fill=Condition))+ geom_point(data= rep1, aes(x=jbin_w), size=3, alpha=0.6)+ geom_point(data= nrep1, aes(x=jbin_nw), size=3, alpha=0.6) + # add the boxplots geom_half_boxplot( data=rep1, aes(group=Bin), position=position_nudge(x=-1.25), side="r", outlier.shape=NA, center=TRUE, errorbar.draw=FALSE, width=.5, alpha=0.6)+ geom_half_boxplot( data=nrep1, aes(group=Bin), position=position_nudge(x=-1.0), side="r", outlier.shape=NA, center=TRUE, errorbar.draw=FALSE, width=.5, alpha=0.5)+ # Add the violin plots for the different bins geom_half_violin( data = rep1, aes(group=Bin), position=position_nudge(x = nudge_vp), side ="l") + geom_half_violin( data = nrep1, aes(group=Bin), position=position_nudge(x = nudge_vp), side ="l") + # # Additional seetings scale_fill_viridis(discrete = TRUE,begin=0.7, end=0.3, alpha=0.8)+ scale_color_viridis(discrete=TRUE,begin=0.7, end=0.3,alpha=0.8)+ scale_x_continuous(name="Pattern Type",breaks=c(0,2,5,8,11,14),labels=c("End.Train","Train-Med","Proto", "New-Low","New-Med" ,"New-High"))pe3rep1=subset(dCatAvg, dCatAvg$condit=="rep" & rt<5000)nrep1=subset(dCatAvg, dCatAvg$condit=="nrep" & rt<5000)set.seed(521)rep1$jbin_w <- jitter(rep1$Bin, amount=.27) -0.3nrep1$jbin_nw <- rep1$jbin_w[1:nrow(nrep1)] + 0.6pe4 <- dCatAvg %>% filter(Stage!="Test") %>% ggplot( aes(x=Bin, y= rt, color =condit, group=condit, fill=condit))+ geom_point(data= rep1, aes(x=jbin_w), size=3, alpha=0.6)+ geom_point(data= nrep1, aes(x=jbin_nw), size=3, alpha=0.6) + # add the boxplots geom_half_boxplot(data=rep1, aes(group=Bin), position=position_nudge(x=-1.25), side="r", outlier.shape=NA, center=TRUE, errorbar.draw=FALSE, width=.5, alpha=0.6)+ geom_half_boxplot(data=nrep1, aes(group=Bin), position=position_nudge(x=-1.0), side="r", outlier.shape=NA, center=TRUE, errorbar.draw=FALSE, width=.5, alpha=0.5)+ # Add the violin plots for the different bins geom_half_violin(data = rep1, aes(group=Bin), position=position_nudge(x = nudge_vp), side ="l") + geom_half_violin(data = nrep1, aes(group=Bin), position=position_nudge(x = nudge_vp), side ="l") + # # Additional seetings scale_fill_viridis(discrete = TRUE,begin=0.7, end=0.3, alpha=0.8)+ scale_color_viridis(discrete=TRUE,begin=0.7, end=0.3,alpha=0.8)+ scale_x_continuous(name="Pattern Type",breaks=c(2,6,10,14,18),labels=c("Trained-Med","Prototype", "New-Low","New-Med" ,"New-High"))+ facet_wrap(~Stage)pe4``````{r fig.width=12,fig.height=9}#| eval: false#| include: false# other settings for stylenudge_vp= -1.3spacing_factor=3dCatAvg$Bin <- as.numeric(dCatAvg$Pattern.Type)*spacing_factorrep1=subset(dCatAvg, dCatAvg$condit=="rep")nrep1=subset(dCatAvg, dCatAvg$condit=="nrep")set.seed(521)rep1$jbin_w <- jitter(rep1$Bin, amount=.27) -0.3nrep1$jbin_nw <- rep1$jbin_w[1:nrow(nrep1)] + 0.6pe3 <- ggplot(data=dCatAvg, aes(x=Bin, y= propCor, color =condit, group=condit, fill=condit))+ geom_point(data= rep1, aes(x=jbin_w), size=3, alpha=0.6)+ geom_point(data= nrep1, aes(x=jbin_nw), size=3, alpha=0.6) + # add the boxplots geom_half_boxplot( data=rep1, aes(group=Bin), position=position_nudge(x=-1.25), side="r", outlier.shape=NA, center=TRUE, errorbar.draw=FALSE, width=.5, alpha=0.6)+ geom_half_boxplot( data=nrep1, aes(group=Bin), position=position_nudge(x=-1.0), side="r", outlier.shape=NA, center=TRUE, errorbar.draw=FALSE, width=.5, alpha=0.5)+ # Add the violin plots for the different bins geom_half_violin( data = rep1, aes(group=Bin), position=position_nudge(x = nudge_vp), side ="l") + geom_half_violin( data = nrep1, aes(group=Bin), position=position_nudge(x = nudge_vp), side ="l") + # # Additional seetings scale_fill_viridis(discrete = TRUE,begin=0.7, end=0.3, alpha=0.8)+ scale_color_viridis(discrete=TRUE,begin=0.7, end=0.3,alpha=0.8)+ scale_x_continuous(name="Pattern Type",breaks=c(2,5,8,11,14),labels=c("Train-Med","Proto", "New-Low","New-Med" ,"New-High"))+ facet_wrap(~Stage)pe3rep1=subset(dCatAvg, dCatAvg$condit=="rep" & rt<5000)nrep1=subset(dCatAvg, dCatAvg$condit=="nrep" & rt<5000)set.seed(521)rep1$jbin_w <- jitter(rep1$Bin, amount=.27) -0.3nrep1$jbin_nw <- rep1$jbin_w[1:nrow(nrep1)] + 0.6pe4 <- dCatAvg %>% filter(Stage!="Test") %>% ggplot( aes(x=Bin, y= rt, color =condit, group=condit, fill=condit))+ geom_point(data= rep1, aes(x=jbin_w), size=3, alpha=0.6)+ geom_point(data= nrep1, aes(x=jbin_nw), size=3, alpha=0.6) + # add the boxplots geom_half_boxplot(data=rep1, aes(group=Bin), position=position_nudge(x=-1.25), side="r", outlier.shape=NA, center=TRUE, errorbar.draw=FALSE, width=.5, alpha=0.6)+ geom_half_boxplot(data=nrep1, aes(group=Bin), position=position_nudge(x=-1.0), side="r", outlier.shape=NA, center=TRUE, errorbar.draw=FALSE, width=.5, alpha=0.5)+ # Add the violin plots for the different bins geom_half_violin(data = rep1, aes(group=Bin), position=position_nudge(x = nudge_vp), side ="l") + geom_half_violin(data = nrep1, aes(group=Bin), position=position_nudge(x = nudge_vp), side ="l") + # # Additional seetings scale_fill_viridis(discrete = TRUE,begin=0.7, end=0.3, alpha=0.8)+ scale_color_viridis(discrete=TRUE,begin=0.7, end=0.3,alpha=0.8)+ scale_x_continuous(name="Pattern Type",breaks=c(2,6,10,14,18),labels=c("Trained-Med","Prototype", "New-Low","New-Med" ,"New-High"))+ facet_wrap(~Stage)pe4``````{r fig.height=10,fig.width=12}#| eval: false#| include: falsenbins=20binSize=225/nbinsdCatTrainBin <- dCatTrain %>% mutate(Trial.Bin=cut(trial,breaks=nbins,labels=FALSE)) %>% group_by(id,condit,Trial.Bin) %>% summarise(nCorr=sum(Corr),propCor=nCorr/binSize,rtMean=mean(rt)) %>% ungroup() %>% group_by(condit) %>% mutate(sbjAvg=mean(propCor)) dCatTrainBin$id <- factor(dCatTrainBin$id,levels=unique(dCatTrainBin$id))dCatTrainBin %>% filter(condit=="rep") %>% ggplot(aes(x=Trial.Bin,y=propCor,col=condit))+ stat_summary(geom="point",shape=0,fun="mean")+ stat_summary(geom="line",fun="mean",col="red")+facet_wrap(~id)+ylim(c(0,1))+ ggtitle("Hu & Nosofsky Experiment 2 - Learning. Rep Subjects.")dCatTrainBin %>% filter(condit=="nrep") %>% ggplot(aes(x=Trial.Bin,y=propCor,col=condit))+ stat_summary(geom="point",shape=2,fun="mean",col="lightblue")+ stat_summary(geom="line",fun="mean",col="lightblue")+facet_wrap(~id)+ylim(c(0,1))+ ggtitle("Hu & Nosofsky Experiment 2 - Learning. NRep Subjects.")``````{r fig.height=10,fig.width=12}#| eval: false#| include: falsenbins=30binSize=floor(225/nbins)dCatTrainBin <- dCatTrain %>% mutate(Trial.Bin=cut(trial,breaks=nbins,labels=FALSE))%>% group_by(id,condit,Trial.Bin) %>% summarise(nCorr=sum(Corr),propCor=nCorr/binSize,rtMean=mean(rt),trainAvg=mean(trainAvg),nTrain=max(nTrain)) %>% ungroup() %>% group_by(condit) %>% mutate(sbjAvg=mean(propCor)) %>% mutate(grpRank=factor(rank(-trainAvg)),id=factor(id)) %>% arrange(-trainAvg) %>% as.data.frame() dCatTrainBin$id <- factor(dCatTrainBin$id,levels=unique(dCatTrainBin$id))dCatTrainBin %>% filter(condit=="rep") %>% ggplot(aes(x=Trial.Bin,y=propCor,col=condit))+ stat_summary(geom="point",shape=0,fun="mean")+ stat_summary(geom="line",fun="mean",col="red")+facet_wrap(~id)+ylim(c(0,1))+ ggtitle("Hu & Nosofsky Experiment 2 - Learning. Rep Subjects.")dCatTrainBin %>% filter(condit=="nrep") %>% ggplot(aes(x=Trial.Bin,y=propCor,col=condit))+ stat_summary(geom="point",shape=2,fun="mean",col="lightblue")+ stat_summary(geom="line",fun="mean",col="lightblue")+facet_wrap(~id)+ylim(c(0,1))+ ggtitle("Hu & Nosofsky Experiment 2 - Learning. NRep Subjects.")``````{r}library(afex)# aov_ez("id",data=dc,"New.High",between="condit")# aov_ez("id",data=dCatAvg2,"propCor",between="condit",within = c("Pattern.Type2"))# aov_ez("id",data=dCatAvg,"propCor",between="condit",within = c("Pattern.Type"))hd <- dcp %>%filter(Pattern.Type2=="New-High")hd2 <- dcp %>%filter(Pattern.Type2=="New-High") %>%group_by(id,condit,cq) %>%summarise(propCor=mean(propCor))# aov_ez("id",data=hd2,"propCor",between=c("condit","cq"))# aov_ez("id",data=hd,"propCor",between=c("condit","cq"),within=c("Category"))# aov_ez("id",data=dc,"New-High",between=c("condit","cq"),within=c("Category"))lme4::lmer(New.High~condit + (1|id),data=dc) %>%anova()lme4::lmer(New.High~condit*cq + (1|id),data=dc) %>%anova()lme4::lmer(New.High~condit + (1|id),data=dc) %>%anova()lme4::lmer(New.High~End.Training + (1|id),data=dc) %>%anova()lme4::lmer(New.High~End.Training+condit + (1|id),data=dc) %>%anova()dc %>% lme4::lmer(New.High~End.Training+(condit*cq) + (1|Category)+(1|id),data=.) %>%anova()dc2%>%aov(New.High~End.Training+(condit*cq),data=.) %>%anova()dCatAvg4 <- dCatAvg2 %>%ungroup() %>%group_by(condit)%>%mutate(r=ntile(propCor,3)) %>%group_by(id,condit,Pattern.Type2,r) %>% dplyr::summarise(propCor=mean(propCor)) %>%ungroup() typeCounts <- dCat %>%group_by(id,Phase2,Pattern.Type) %>%summarise(n=n())typeCategoryCounts <- dCat %>%group_by(id,Phase2,Category,Pattern.Type) %>%summarise(n.trials=n())typeCounts2 <- typeCounts %>%group_by(Phase2,Pattern.Type) %>%summarise(N.Trials=mean(n),TrialsPerCategory=as.integer(N.Trials/3))typeCategoryCounts2 <- typeCategoryCounts %>%group_by(Phase2,Category,Pattern.Type) %>%summarise(N.Trials=mean(n.trials))``````{r}distGradient <- dc %>%pivot_longer(cols=c(EndTrain.Minus.HighDistort,TrainedItem.Minus.HighDistort, MedDistort.Minus.HighDistort,LowDistort.Minus.HighDistort, Prototype.Minus.HighDistort),names_to ="Distortion.Level",values_to="PropCor")# Performance correlation matricesdc %>%ungroup() %>%select(End.Training,New.Low,Prototype,New.Med,New.High) %>%cor()dc %>%filter(condit=="rep") %>%ungroup() %>%select(End.Training,New.Low,Prototype,New.Med,New.High) %>%cor()dc %>%filter(condit=="nrep") %>%ungroup() %>%select(End.Training,New.Low,Prototype,New.Med,New.High) %>%cor()# High Distortion decrement correlation matricesdc %>%filter(condit=="rep") %>%ungroup() %>%select(End.Training,Prototype.Minus.HighDistort, TrainedItem.Minus.HighDistort, LowDistort.Minus.HighDistort, MedDistort.Minus.HighDistort, EndTrain.Minus.HighDistort) %>%cor()dc %>%filter(condit=="nrep") %>%ungroup() %>%select(End.Training,Prototype.Minus.HighDistort, TrainedItem.Minus.HighDistort, LowDistort.Minus.HighDistort, MedDistort.Minus.HighDistort, EndTrain.Minus.HighDistort) %>%cor()dc %>%ungroup() %>%select(End.Training,Prototype.Minus.HighDistort, TrainedItem.Minus.HighDistort, LowDistort.Minus.HighDistort, MedDistort.Minus.HighDistort, EndTrain.Minus.HighDistort) %>%cor()```[Link to preprocessing code](read_22.html)```{r fig.height=10,fig.width=11}#| eval: false#| # dRecAvg %>% ggplot(aes(x=Block,y=propCor,col=condit))+# stat_summary(geom="point",fun="mean")+stat_summary(geom="line",fun="mean")+facet_wrap(~id)dRecAvg %>% filter(condit=="rep") %>% ggplot(aes(x=Block,y=propCor,col=condit))+ stat_summary(shape=0,geom="point",fun="mean")+ stat_summary(geom="line",fun="mean",col="red")+facet_wrap(~id)+ylim(c(0,1))+ ggtitle("Hu & Nosofsky Experiment 1 - Learning. Rep Subjects.")dRecAvg %>% filter(condit=="nrep") %>% ggplot(aes(x=Block,y=propCor,col=condit))+ stat_summary(shape=2, geom="point",fun="mean",col="lightblue")+ stat_summary(geom="line",fun="mean",col="lightblue")+facet_wrap(~id)+ylim(c(0,1))+ facet_wrap(~id)+ggtitle("Hu & Nosofsky Experiment 1 - Learning. NRep Subjects.")```# R packages used```{r}##| eval: false# grateful::cite_packages(output = "paragraph",pkgs="Session",# out.dir = "assets", cite.tidyverse=TRUE)pkgs <- grateful::cite_packages(output ="table",pkgs="Session",out.dir = here::here("assets"), cite.tidyverse=TRUE, omit=c("colorout","viridis"))# read in assets/grateful-refs.bib file# ref_file <- here::here("assets","grateful-refs.bib")# load file#bib <- bibtex::read.bib(ref_file)#pkgs <- scan_packages()knitr::kable(pkgs)usedthese::used_here()sessionInfo()```